[리뷰] 머신러닝 리스크 관리 with 파이썬
in Review on Review, Book, Ml, Python, 머신러닝, 리스크관리, 안정성, 신뢰성, Xai, Nist, Aia, 디버깅, 편향, 보안, 위험관리, Xgboost, 고위험

한빛미디어출판사의"머신러닝 리스크 관리 with 파이썬(패트릭 홀, 제임스 커티스, 파룰 판데이 저/윤덕상, 이상만 역 외 3명)"를 읽고 작성한 리뷰입니다.
XAI, 모델 디버깅, 편향, 보안 등의 주제를 중심으로 머신러닝 리스크의 대처법을 다룬 책이다. 인공지능 위험관리 프레임워크, Python 예제, 사례연구를 통해 추상적인 내용을 구체적으로 이해시켜 준다는 점이 이 책의 백미이다.
머신러닝 시스템의 리스크에는 어떤 것들이 있을까?
머신러닝이 흔히 활용되는 분야인 의료나 자율주행 분야는 인명사고로 이어질 수 있는 분야이고 금융거래는 재산피해로 이어진다. 인종차별 편향의 경우 윤리적인 문제로 이어지며 그 외 머신러닝 시스템 자체의 보안 및 프라이버시 유출과 관련된 부분도 머신러닝 리스크로 볼 수 있다.
이 책에서 다루는 주제가 머신러닝 리스크이다. 이 유형들에 대한 정의에서 출발하여 실제 케이스를 분석해보고 실습을 통해 리스크를 최소화 할 수 있는 다양한 방법을 학습하도록 구성되어있다.
문제는 이러한 내용들이 너무 추상적인 내용이라 이해가 쉽지 않다는 점에서 출발한다. 이 책은 이 문제를 해결하고자 최대한 구체적으로 개념들을 열거하기 위한 몇가지 장치를 사용한다. 사례, 구체화 된 프레임워크의 활용, Python 실습이 해결책으로 등장하는데 이 책의 가장 큰 장점이기도 하다.
각 장 말미에는 해당 주제에 대한 구체적인 사례를 소개한다. 해당하는 하나의 구체적인 사례이기에 머신러닝 지식이 없는 사람도 흥미롭게 읽을 수 있는 부분이며 이런 구체적인 실제 생활의 사례는 추상적인 개념을 이해하는데 큰 도움이 된다.
예를 들면 1장의 “질로우 아이바잉“을 소개할 수 있다. 3년 전 즈음 미국 주식에 투자하면서 각광받던 부동산 프롭테크의 강자인 질로우의 주가가 하루사이에 급락하여 관련 주식을 검색한 기억이 있다. 부동산 종목에 큰 관심을 두지 않던 때라 자세히 알아보지는 않았지만 머신러닝 시스템의 결함때문에 회사가 큰 손실을 보았다는 기사는 꽤 흥미로운 부분이었다.
당시의 기억 덕분에 1장의 사례연구는 꽤 재미있게 읽을 수 있었다. 요약하자면 질로우 주가 급락의 원인은 아이바잉 사업때문이었다. 이는 주택을 매입 후 되팔아 시세차익으로 수익을 창출하는 사업인데 문제는 이 사업의 판단을 머신러닝 시스템에 맡겼다는 것이고 머신러닝 시스템의 부정확성 때문에 회사에 큰 빚이 생기게 된다. 손실액만큼 감가상각을 진행했고 그 액수만큼 주가에 반영되어 하락으로 이어진 것이다. 이는 머신러닝 리스크의 대표적인 사례라 할 수 있다.
두번째로 소개한 프레임워크는 NIST에서 제작한 “인공지능 위험관리 프레임워크(NIST AI RMF)”이다. 
위험관리 분야 및 절차를 정의하고 설계하는 데 있어 몇 안되는 저자만의 경험만 활용한다는 것은 다소 위험한 부분이다. 보다 구체적으로 다양한 사람들의 피드백이 수렴하는 권위있는 가이드를 중심으로 저자들이 중요하다고 생각하는 문제를 서술하고 있어 믿고 볼 만한 책으로 보인다.
2024년 3월 유럽연합 의회가 인공지능법(AI Act)을 통과시킨 것을 시작으로 앞으로 전 세계적에 인공지능에 대한 규정, 규제, 규칙 등이 제정이 가속화 될 것 같다. 다양한 지침을 만족시키기 위한 측면에서도 이 책은 높은 가치를 지녔다고 생각하며 더욱이 이런 분야를 중심으로 저술된 책은 그동안 찾아보지 못했기에 그 희소성이 더욱 귀중한 책이라 하겠다.
세번째로 소개할 Python 실습 부분은 이 책의 백미라고 할 수 있다. 1부에 이론적인 내용들이 서술되어 있긴 하지만 쉽게 이해되지 않는 부분들이 많다.
추상적인 내용이 자주 등장하며 행적적인 측면의 가이드 제시의 비중이 커 구체적으로 이해하기 어려움이 있는데 2부의 실습들이 1부가 말하고자 하는 부분들을 구체적으로 소개한다. 실습을 통해 추상적인 개념들을 명확히 이해할 수 있으며 이 책에서 가장 마음에 드는 부분이기도 하다.
이 책에서 다루는 내용을 간단히 요약한 부분이 1장이다. 리스크 관리에 대한 전반적인 방안을 제시한 후 구체적인 대응책은 2장에서 부터 시작된다. 요약하자면 XAI, 모델 디버깅, 편향, 보안 측면으로 나눌 수 있다.
먼저 XAI파트는 이론은 2장에 상세하게 설명하고 실습은 6장, 7장에서 진행한다. XAI란 인공지능의 내부에 감춰진 블랙박스를 열어보려는 기법이다. XAI를 통해 인공지능을 해석해보는 과정은 모델 디버깅, 보안 등을 위한 필수적인 사전 과정이다.
LIME, SHAP, 특성의 부분종속도, 개별조건부기대 등을 소개하고 있으며 아래 그림은 각각 XGBoost 기반의 정형 데이터 분석 과정 및 비정형 이미지 데이터의 XAI 분석을 다룬 그림이다. 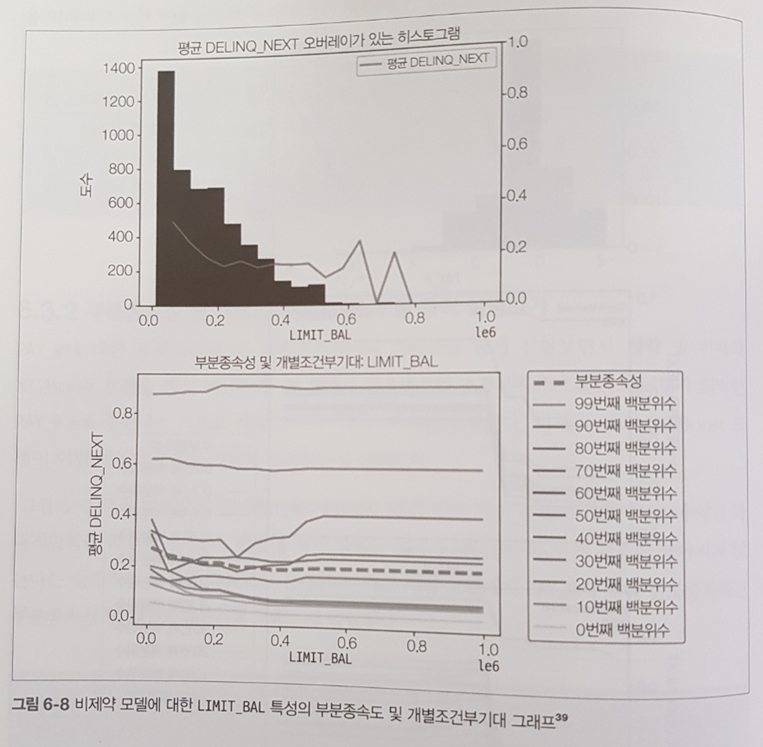
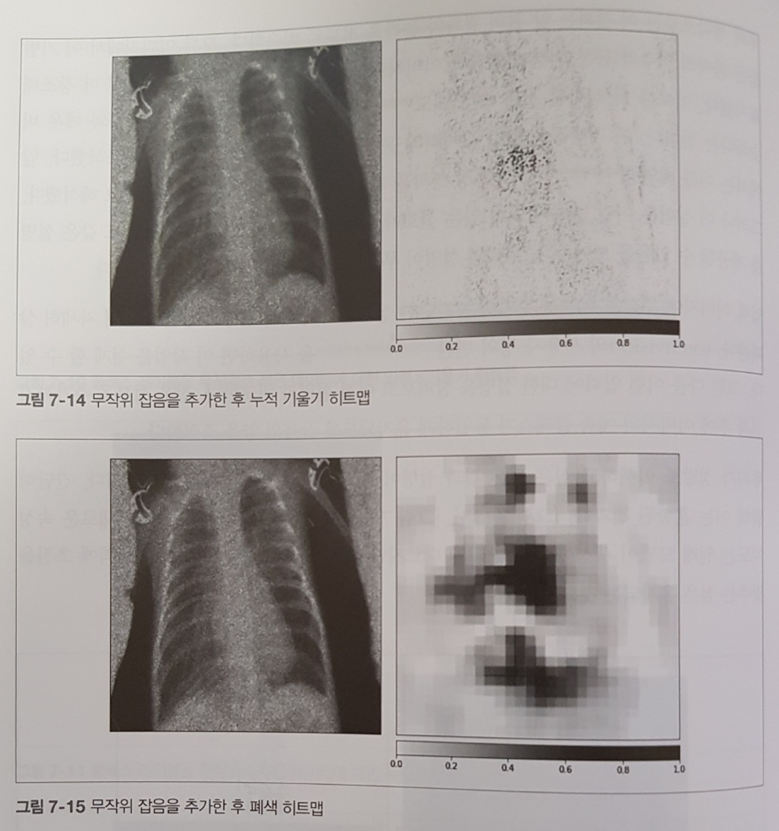
이어서 디버깅 파트를 소개한다. 이론은 3장에서 소개하고 실습은 마찬가지로 정형 데이터는 5장, 비정형 데이터는 9장에서 소개한다. 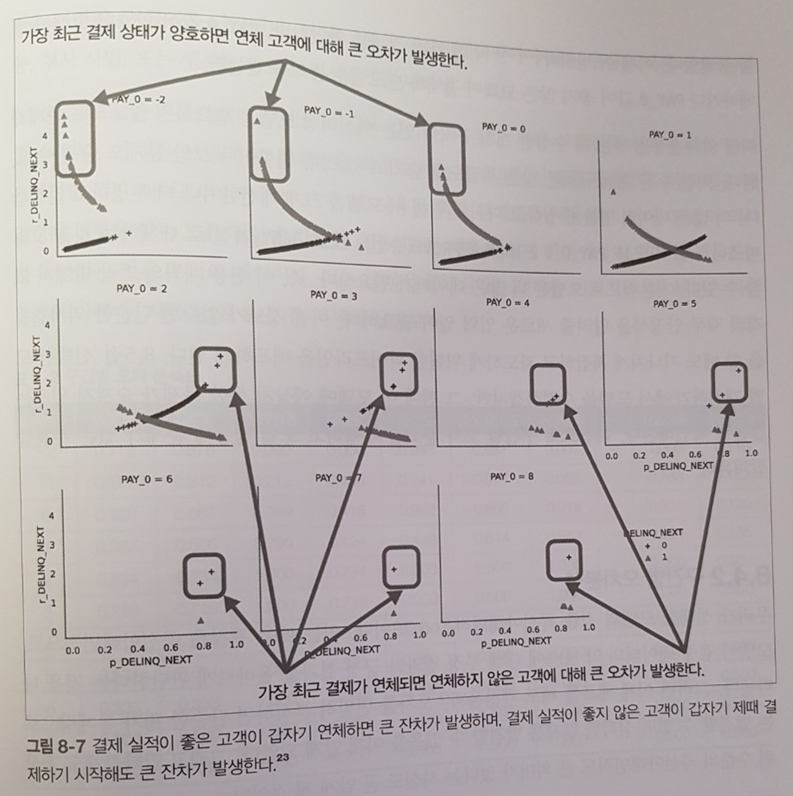
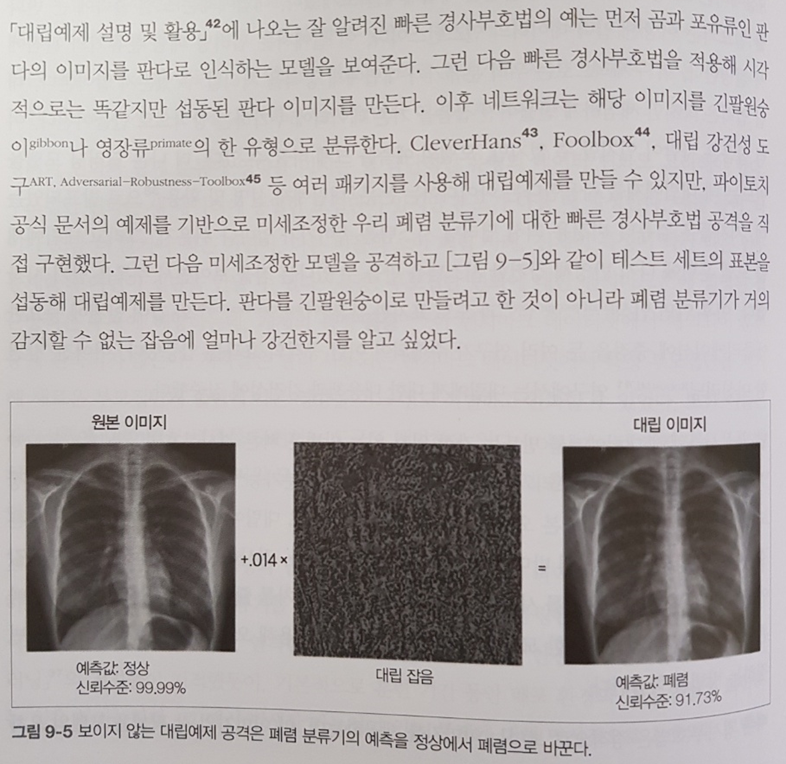
비정형데이터 디버깅에 있어 대립예제를 활용하는 것이 흥미롭다. 이 기법은 5장 보안파트에서 공격 수단 중 하나로 소개되는 기법이기도 하다. 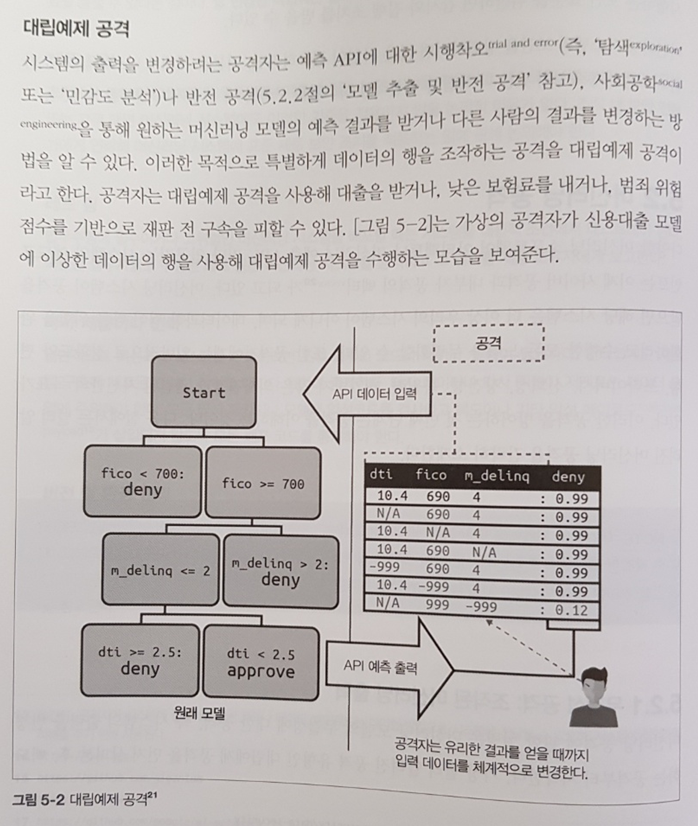
디버깅 이후에는 편향 테스트에 대하여 학습한다. 이론은 4장, 실습은 10장에서 진행된다. 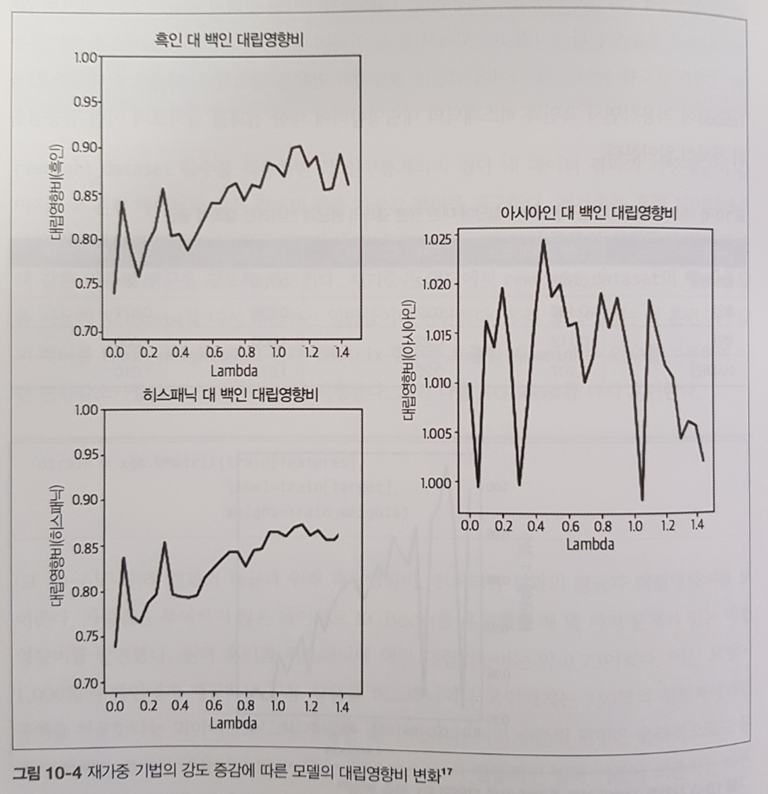
마지막으로 보안에 관련된 주제는 이론은 5장에서 소개하고 있고, 실습은 거의 모든장에 포함되어있다고 보면 되는데 그 중에서도 10장에서 레드팀을 구성하는 방법은 꽤 흥미로운 부분이다. 단조제약조건 위반을 통해 백도어 유무를 판별하는 방법이 신선하다. 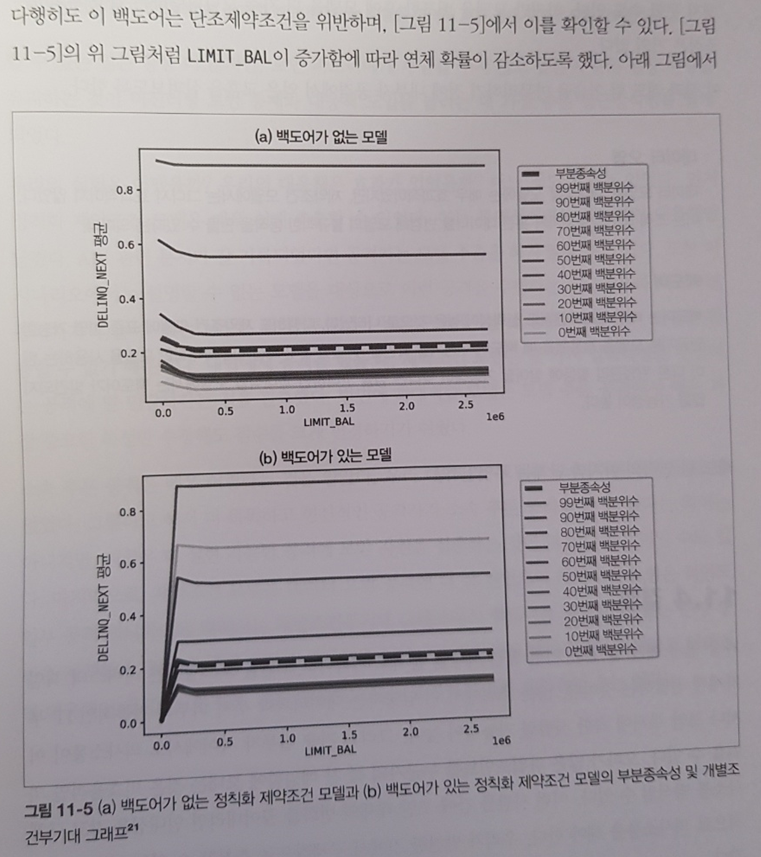
각각의 기법을 상세하게 설명하기에는 지루한 리뷰가 될 것 같아서 내용을 구성하는 큰 그림만 간략히 소개해보았다. 원하는 기술이나 방법을 찾아보는데 도움이 될 것이다.
이처럼 이 책의 3가지 큰 장점을 살펴보았다. 무엇보다 리스크 주제를 통합적으로 다룬 책이 희귀한만큼 머신러닝 시스템 운영자 입장에서는 필독서가 아닐까 싶다. 참고로 부록에는 컬러 이미지가 수록되어 있어 색상 정보 없이 직관적으로 파악하기 힘든 일부 그림들을 가독성있게 파악하는데 도움이 될 것이다.
