[리뷰] 딥러닝과 바둑
in Review on Review, Book, Python, Deep, Leraning, 바둑, Go, Alphago, Alphazero, Bot, 알파고, 알파고제로

한빛미디어출판사의"딥러닝과 바둑(막스 펌펄라, 케빈 퍼거슨 저/권정민 역)"를 읽고 작성한 리뷰입니다.
이 책이 다루는 내용은 한 마디의 질문으로 요약할 수 있다.
“알파고는 어떻게 만드는 걸까?”
알파고 덕분에 AI를 심도있게 연구하고 학습하는 이들이 많아졌지만, 정작 알파고와 유사한 봇을 개발한 사람은 극소수가 아닐까 싶다. 당장 업무와 산업 분야에 관련되거나 취업과 관련된 지식이 아닐뿐더러 게임 분야에 관심이 없거나 특히 바둑에 대한 지식이 전무한 사람은 넘어야 할 장벽이 많기 때문일 것이다.
그럼에도 알파고를 구현하는 것은 큰 의미가 있다. AI 열풍을 견인한 기술의 실체를 최대한 밑바닥까지 들여다 볼 수 있는 지적 호기심을 채울 수 있을 뿐더러, 다소 부풀려진 AI에 대한 환상을 제대로 측정할 수 있는 기술적 안목을 얻을 수 있고, 우주의 나이보다도 훨씬 많은 경우의 수와 불가능에 가까운 연산에 도전해 볼 수 있다는 것은 분명 흥미로운 일이다.
복기(復碁)
바둑에는 복기라는 용어가 있다. 게임에서 패배한 경우 결정적인 패착수를 둔 상황으로 돌아가 A, B 중 어떤 수를 선택해야 했는지 곱씹어 보는 과정이다.
재미있는 것은 인생에도 비슷한 느낌의 선택을 필요로 하는 순간이 온다는 점이다. 사람마다 다르겠지만 개인적으로 선택의 순간에서 판단이 어려울 때 바둑을 두곤 했다. 착수 A, B 선택의 순간에서 드는 느낌이 묘하게 인생에서의 선택지와 비슷한 색상, 감, 냄새 같은 것이 느껴질 때가 있는데 승패 결과에 따라 인생에서도 비슷한 느낌의 선택지를 고른다.
정작 알파고가 놀라웠던 것은 이세돌 9단에게 승리한 것이 아니라 이 표현 못할 감의 영역을 어떤 방법으로 수치화했는지 궁금해서였다. 그 방법을 알면 인생의 답을 얻는데 큰 도움이 되지 않을까라는 호기심이 계기가 되어 AI와 관련된 서적이나 논문을 읽는 것이 일상의 취미가 되어버렸다.
잠시 바둑의 이야기를 구구절절 늘어놓은 것은 두가지 목적에서다. 하나는 바둑을 잘 모르는 분들께 알파고를 구현해보는 것이 얼마나 의미가 될 수 있는지 강조하고 싶었고, 다른 하나는 독자분들이 본 도서의 진가를 몰라보고 일본식 전통 의상을 입고있는 표지에 비호감 혹은 고리타분함이라는 선입견이 생겼을까 우려되었기 때문이다.
베타고(BetaGo)
본 도서의 두 저자 막스와 케빈은 알파고의 동작 원리에 대한 궁금증을 파헤치고자 알파고와 유사한 오픈소스 바둑봇인 베타고를 만든 장본인들이다. 베타고의 성능이 궁금하여 직접 겨뤄봤는데 나는 고작 타이젬 바둑 2단의 실력이기에 베타고의 실력을 가늠할 수는 없었지만 초고수의 느낌은 지울 수 없었다.
더불어 딥마인드 알파고팀의 대표인 소레이 그리펠이 알파고부터 이후의 확장에 대한 여정과 더불어 현대 AI를 구성하는 주요 알고리즘을 익힐 수 있다고 추천사를 남겼기에 더욱 책의 내용에 신뢰가 갔다. 책을 다 읽고난 지금 시점에서는 신뢰의 수준을 넘어서 이 책이 없었다면 개인적으로 알파고를 만드는 길이 얼마나 요원했을지 아찔한 생각이 들어 감사의 마음이 절로 들었다. 이전에도 이미 알파고를 만들고 말겠다는 덕질의 일환으로 여러 책과 논문, 레퍼런스 및 오픈소스를 읽어왔으나 생각보다 다양한 기술들이 필요하고 고민거리가 많아 진척이 쉽지 않았기 때문이다.
책의 난이도와 선수지식
제목에서 알 수 있듯 본 도서의 내용은 조금 어렵다. 먼저 기본적인 파이썬 및 프로그래밍 관련 지식이 필요하다. 파이썬의 문법은 물론 배포, Flask, AWS 배포와 연동, 프로토콜 지식 등이 등장한다.
또한 일정 수준 이상의 딥러닝 지식이 필요한데 CNN 모델과 SGD 보다 성능이 좋은 에이다그래드, 에이다델타와 같은 경사법을 이해할 수 있는 수준이면 좋다. 마지막으로 행위자-비평가 학습(Actor-Critic Learning) 및 DQN 등의 강화학습에 대한 선수 지식이 있다면 책을 이해하는데 순조로울 것으로 예상한다. 더불어 바둑에 대한 도메인 지식(?)이 은근히 중요하다.
대신 바둑을 좋아하는 사람이라면 본 도서에 충분히 도전할만하다. 즐기는 자는 천재도 노력하는 사람도 이길 수 없다고 논어(論語) 옹야편(雍也篇)에 언급되어 있으니 말이다. 마찬가지로 강화학습이나 딥러닝의 입문을 뗀 분들도 도전해볼만 하다. Python과 알고리즘에 자신있는 분들도 마찬가지이다.
세가지 경우에 모두 해당되지 않는 분일지라도 반드시 알파고를 만들겠다는 의지가 강력한 분이라면 도전을 권유드린다. 1장에는 딥러닝에 대한 기초 설명이, 2장에는 바둑의 룰에 관한 설명이, 부록에는 선형대수와 미적분 등에 대한 설명이 언급되어있어 도전해볼 만하다. 부족한 부분은 검색이나 유튜브 등을 통해 보완하며 책을 읽어나간다면 최단 시간 내 가장 큰 효과를 얻을 수 있을 것이다.
본 도서가 가지는 장점을 요약하면 다음과 같다.
알파고를
실제로 구현할 수 있다.
저자들이 실제 베타고를 구현해 본 경험이 있기 때문에 연구 및 구현 능력에 의구심을 품지 않아도 된다.베타고의 성능을 높이기 까지의
시행착오와 일련의 과정들이 잘 녹아있다.
처음부터 알파고제로 수준의 동작방식이나 원리를 설명하고 구현체의 소스를 설명하는 방식으로 구성되었다고 한들 충분히 가치있는 책이 되었을것이다.하지만 본 도서는 한 단계 더 나아가 저자들이 겪었던 시행 착오들을 언급하고 있다. 그 과정에서
왜 딥러닝 모델을 CNN으로 바꾸었는지, Input 데이터의 평탄화 작업(Flatten)을 왜 회피하였는지, 몬테카를로 트리 탐색 기법을 강화학습과 결합하여 사용하였는지등의 그동안 궁금했던 지식들을 함께 익힐 수 있었다.점 A 하나만으로는 벡터 혹은 함수를 만들 수 없고, 미래의 점 C는 예측이 어려워진다. 본 도서의 구성은 점 A는 물론 A에 대한 개선안인 점 B를 설명하기에 C를 유추해볼수도 있고 나중에 우리가 성능을 보완할 여지인 점 D도 어렵지 않게 추정해볼 수 있다. 더불어 개선 과정에서 딥러닝, 탐색 알고리즘, 강화학습 등 각각의 활용 방법이나 필요성의 진정한 의미에 정통할 수 있다.
실 서비스를 위한 고민의 흔적들- 실제 봇과의 대국을 위한 원시
CLI(명령 커맨드 라인 방식) 부터WEB Front-End UI방식까지 인터페이스 또한 상세히 다룸으로써 아는데 그치는 수준이 아닌 서비스가 가능한 BOT을 구현할 수 있다. - GPU 자원이 부족한 독자를 위해 모델 다운로드 등의 대안이 제시될 뿐만 아니라 최소 과금체계로
AWS클라우드를 활용할 수 있도록 가이드한다. - 사람과의 대국 수준을 뛰어넘어 다른이가 만든
BOT과의 대국 및 성능평가 방법도 기술한다. - 프로기사 수준의 기보를 학습하는 방법이 자세히 설명되어있다.
SGF 대국 데이터를 다운받아 전처리 후 활용하는 방법을 통해 실무에 적용할 수 있는 전처리 기법도 배울 수 있다. - 바둑 전용 프로토콜
GTP및 Front-End 기술도 활용한다.
- 실제 봇과의 대국을 위한 원시
번역 수준이 뛰어나다.
마지막으로 본 도서의 주요 내용을 요약하며 리뷰를 마친다.
딥러닝과 바둑의 기초 (1장 ~ 2장)
원시 바둑봇만들기 (3장)- 바둑의 게임 수행에 필요한 전반적인 기능을 모두 구현한다.
- Enum(흑,백), 보드, 게임 국면상태(GameState) 등 필수 기능 구현
- 동형반복 규칙을 활용한 패, 돌의 이음 파악 방법, 착수/한수쉼/던지기 등 규칙 구현
- 조브리스트 해싱 알고리즘을 이용한 속도 개선
- 사람 및 다른 BOT과의 대국 가능

- 바둑의 게임 수행에 필요한 전반적인 기능을 모두 구현한다.
- 트리 탐색 (4장)
- 결정론적 완전 정보 게임에 대한 이해
- 미니맥스
- 모든 경로를 탐색하기에 정확도는 높지만 연산속도에 치명적. 틱택도같은 매우 간단한 게임에만 적용가능하다.
- 위치 평가 함수를 활용한 깊이 가지치기
- 알파-베타 가지치기
- 충분히 최악인 수가 파악되었으면 상대의 수는 더이상 고려할 필요가 없으므로 가지치기를 통해 연산량을 줄일 수 있다.
몬테카를로 트리 탐색(MCTS)- 사전 도메인 지식 없이도 임의의 롤아웃을 통해 상태 평가가 가능
- 탐색할 가지를 선택하기 위해 트리 신뢰도 상한선(UCT) 방식을 활용
- 딥러닝 (5장 ~ 8장)
- 신경망의 기본 : MNIST 구현, 역전파, 손실함수, 경사하강법, 활성화함수 등
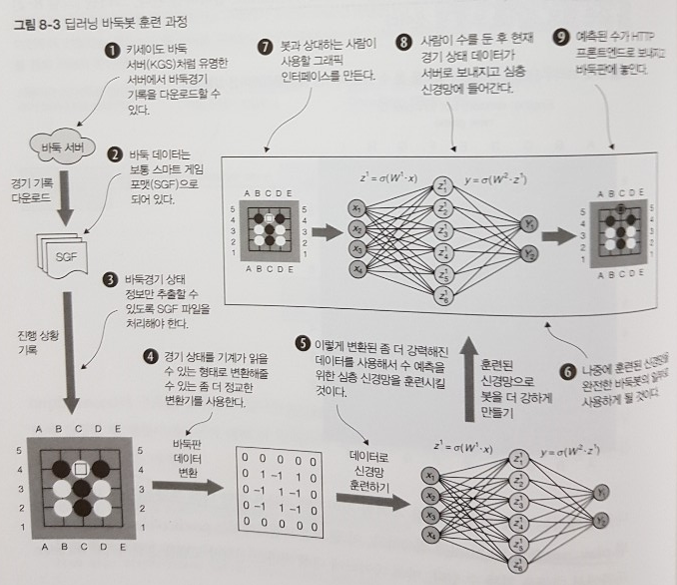
바둑용 신경망설계 : Encoder 구현, MCTS를 활용한 기보 생성, Keras 학습, CNN 모델 구현, 손실함수 및 활성화함수 개선 등- 학습 : SGF 전처리 및 훈련, 에이다그래드를 활용한 신경망 최적화
두번째 바둑봇만들기- HDF5 포맷을 이용한 예측 에이전트 생성
- FLASK를 활용한 HTTP 프런트엔드 앱 개발
- GTP 바둑 프로토콜 사용, AWS 배포, OGS 온라인 바둑서버 연동 등
- 강화학습 적용 (9장 ~ 12장)
상태, 행동, 보상등 강화학습의 기본 정리- 출력 결과에 대한 확률 분포로부터 표본을 추출하여 정책 신경망 구현
- 자체 대국을 통한 실험 데이터 수집
정책 경사 학습: 승리를 이끈 모든 수의 확률을 높이고, 패배에 일조한 수의 확률을 낮춤- 교차 엔트로피 손실함수 적용
행동-가치 함수, Q-학습, 행위자-비평가 학습을 통한 정책 함수 및 가치 함수 활용 등
- 알파고와 알파제로 (13장 ~ 14장)
정책 신경망 2개와 가치 신경망 1개구현- 빠른 정책 신경망과 강한 정책 신경망
- 시뮬레이션 방식, Q값, 유틸리티 값 등 동작방식 구현
강화학습과 트리 탐색의 결합디리클레 잡음, 배치정규화, 잔차 신경망구현