[리뷰] Do it! 자료구조와 함께 배우는 알고리즘 입문
in Review on Review, Book, Python, 자료구조, 알고리즘, Do, It, 테스트, 면접, 입문서, 취업

이지스퍼블리싱출판사의"Do it! 자료구조와 함께 배우는 알고리즘 입문 : 파이썬 편(시바타 보요 저/강민 역)"를 읽고 작성한 리뷰입니다.
본 도서는 Python을 활용한 알고리즘, 자료구조 입문서이다.
[Do it! 자료구조와 함께 배우는 알고리즘 입문]은 시리즈로 간행되어 3년 전 C언어편, 2년 전 Java편에 이어 금년도에 Python편이 나왔다. 쉽게 이해할 수 있는 알고리즘 입문서로 꽤나 정평이 나있었기에 언젠가 한 번 읽어봐야 겠다 싶었는데 드디어 Python편을 처음 접하게 되었다.
본 도서의 장점은 크게 2가지를 들 수 있다.
하나는 C, Java, Python까지 동일한 저자가 시리즈로 간행한 도서이기에
Python만이 가지는 독특한문법이나 패턴을 이해하기 쉽다는 점이다.
다른 입문서와는 달리 책 곳곳에 다른 언어와 어떤 점이 다른지 설명해준다는 측면이 인상적이었다. 예를 들면 타 언어에서 자주 언급되는 Call by Value, Reference 등의 개념이 Python에서는 Call by Object Reference로 사용된다는 등 차이점을 상세히 설명함으로써 다른 언어와 다른 결과에 당황하지 않고 Python에 쉽게 적응하게 해준다.
또 다른 한가지 장점은
실무를 고려한 서적이라는 점이다.
15년 간 프로그래머로 밥먹고 살면서 의외였던 점은 생각보다 학교에서 배운 알고리즘을 사용할 기회가 적었다는 점이다.
물론 알고리즘은 매우 중요하다. 알고리즘 자체에 대한 중요성을 폄하하려기보다는 알고리즘을 실전의 목적과 문제에 맞게 변형하여 빠른 시간내에 생산성을 높이는 실전 감각이 중요하다는 점을 강조하고 싶은 것이다.
대부분의 입문서나 교과서는 뻔하다. 버블, 삽입, 선택, 병합, 퀵 등의 정렬과 선형, 이진, 해시 등의 검색 크게 두 파트로 정리되어있다. 거기에 링크드 리스트와 스택, 큐, 트리 등의 내용이 보태어 진다.
그림으로 볼 때 어떤 방식으로 움직이고, 소스코드는 어떻고, 그리하여 시간복잡도는 어떠하다. CRUD(삽입, 검색, 수정, 삭제)별 시간복잡도가 다를 수 있으므로 상황에 맞게 골라써야 한다. 대부분의 교과서가 지금 언급한 구성에서 크게 벗어나지 않을 것이다.
물론 본 도서도 대부분 위의 구성을 따르지만 앞서 언급한대로 실무에서 활용할 수 있도록 구성된 점이 차별점이다. 약 100 페이지(1/4 정도 분량)를 할애하여 1,2장 알고리즘과 자료구조의 기초를 다룬다.
정수의 합을 계산하는 문제부터 소수를 나열하는 문제까지 기초적인 문제가 매우 다양한 유형으로 소개되어있다. 기초 내용이라고 무시하기 쉽지만 실전에서 수도 없이 자주 맞닥드리는 문제들이다.
더불어 이런 기초에 대한 폭넓은 이해없이는 프로그램을 개발하는데 있어 생산성이 보장되지 않는다. 속도도 느린마당에 이해력이 부족하여 옆의 팀원과 대화조차 안되어 몰래 집에서 혼자 공부하는 서러움을 겪을 수도 있다.
폭넓은 예제를 다루며 여러 단계의 개선 과정을 거치는데 각 과정마다 개선을 시도하려는 접근 방식과 안목이 주옥같다. 실전에서 효율성을 위해 검토하는 방식과 동일하기 때문이다. 1, 2장이 앞에 포진되어 있어 기초를 다룬 장이라고 무시할 것이 아니라 저자의 접근법을 잘 따라간다면 실무에서 놀랄만한 성취를 이룰 수 있다.
더불어 각 과정 마다 독자가 따라오지 못하거나 이해하지 못할 경우를 대비해 상세한 시각화 자료가 제시된다. 시각화도 저자의 관점과 생각에 따라 같은 소스 코드를 두고 비효율적으로 이해하는 선입견이 생길수 있어 주의해야 하는 부분인데 저자가 다년간 알고리즘을 어떻게 시각적으로 쉽고 효율적으로 표현할 수 있을지 고민한 흔적이 역력히 느껴진다.
아래 그림은 이진 검색 알고리즘을 구현하고 테스트하는 예제인데 구현을 넘어서 스스로의 동작 방식을 시각화하여 이해할 수 있는 형태로 프로그램을 개발한다. 스스로 구현한 프로그램의 동작 방식을 명확히 이해하는데 있어 이보다 훌륭한 방법이 있을까 싶다. 
위에서 언급한 구체적인 장점들을 설명하고자 하나의 예시를 선정해 보았다. 2장 마지막 예제 소수 나열하기로 아래 그림은 소수를 나열하는 프로그램을 시각적으로 표현한 부분이다. 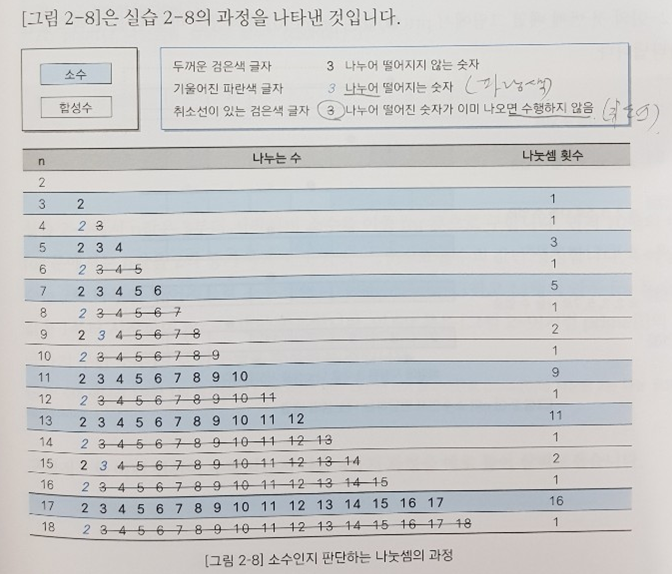
소수는 1과 자기 자신을 제외한 나누어 떨어지는 숫자가 없다는 규칙이 있다. 예를 들어 13이 소수인지 판단하려면 2, 3, … , 12까지의 수들로 13을 나누어 떨어지는지(즉, 나머지가 0인지) 판단하면 된다.
위 그림은 2 ~ 18까지 소수인지 검사하는 과정을 시각화한 그림인데 파랑색 이탤릭체로 나누어 떨어지는 숫자를 표기했고, 나누어 떨어지는 숫자가 하나라도 등장하면 소수가 아니므로 뒤의 숫자는 검사할 필요가 없다는 것을 취소선을 이용해 표기했다. 소수의 나열 과정을 이렇게 직관적으로 표현한 그림은 처음 보는 듯 하다.
여기서 소개를 마쳐도 나무랄 바 없는데 아래 그림과 같이 개선을 시도한다. 2와 3이 소수로 밝혀진 이후에는 두 숫자로 나누어 떨어지지 않는 숫자 N은 두 숫자의 곱 조합인 2 * 2 = 4, 2 * 3 = 6, 3 * 3 = 9 등의 숫자로도 나누어 떨어지지 않음을 알 수 있다. 그럼에도 4, 6, 9로 나눠 떨어지는지 검사하는 것은 비효율적이다. 
따라서 위 그림과 같이 찾아낸 소수를 특정 배열에 저장한 후 해당 수들로만 나눗셈을 하여 나눠 떨어지는지 파악하면 된다.
여기서 한단계 더 나아간다. 아래 그림과 같이 5 * 20과 20 * 5는 대칭 구조를 이룬다. 즉, 특정 수 N이 정사각형의 면적이라 생각하여 한변의 길이로 나누어 떨어지지 않으면 나머지 변의 길이로도 나눠 떨어지지 않음에 착안한다. 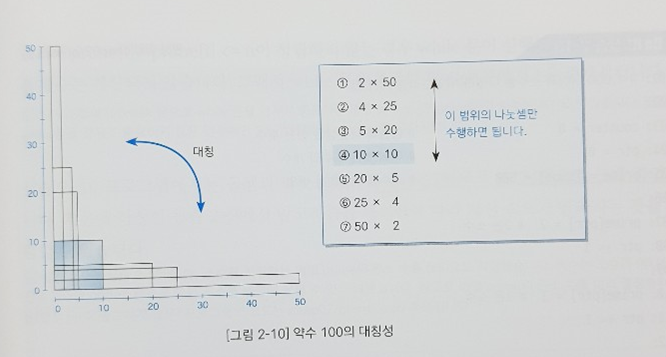
즉, 위 그림의 네모박스와 같이 N 제곱근 이하의 어떤 소수로도 나눠떨어지지 않는다면 소수라고 할 수 있는 것이다.
이렇듯 작은 알고리즘 문제 하나에 있어서도 여러 개선점을 찾고자 노력하고 그 과정을 쉽게 이해할 수 있게 시각적으로 도식화 한 구성이 매력적인 도서라 할 수 있겠다.
3장 이후 이어지는 알고리즘의 핵심 부분도 이러한 기조를 이어나간다. 선형 검색을 개선하기 위해 보초법으로 if문을 제거하는 방법 등 지속적인 알고리즘의 개선 시도는 물론, 이진 검색부터는 데이터가 정렬되어 있어야 한다는 등 전제 조건 등이 명확히 언급된다.
시간복잡도를 설명하는데 있어서도 O(n)의 의미가 n과의 비례 관계를 의미한다는 점과 연속 동작에서의 시간복잡도는 Max 복잡도를 기준으로 함을 분명히 한다. 그동안 만났던 알고리즘 입문서는 이런 핵심에 대한 설명이 누락되어 괜히 이해를 어렵게 하였는데 이런 명쾌한 점이 본 도서의 장점이다.
각 알고리즘별 Trade-Off 관계를 언급함으로써 실전에서 고려해야 할 사항들에 대한 판단을 돕기도 하며, 알고리즘을 이해하고자 밑바닥부터 구현하긴 하지만 실전에서는 어떤 라이브러리를 활용하면 되는지 안내된다. 예를 들면 스택의 경우 collection.deque를, 큐에서는 heapq 모듈을 활용할 수 있음을 알려준다.
재귀 파트야 말로 본 도서의 시각화 자료의 활용이 얼마나 빛을 발하는지 알 수 있는 대목이다. 재귀는 직관적으로 사고하기 어려워 시각화 자료가 정말 중요한 파트인데 각 재귀 흐름 단계별 명쾌한 시각화 자료로 로직이 쉽게 이해된다. 본 도서에서는 다루지 않지만 차후 Dynamic Programming을 배우는데 있어서 튼튼한 기초를 마련할 수 있을 것이다.
정렬 파트 역시 주요 9개 알고리즘을 꼼꼼하게 다루고 있으며 단순 삽입 정렬이 선택 정렬과 비교해 어떤 차이점이 있는지 - 값이 가장 작은 원소를 선택하지 않는다 등 - 언급된 것을 보며 디테일에 적잖이 놀랐다. 학부 시절 둘다 삽입인데 이름은 한쪽만 삽입이라 해메였던 기억이 떠올랐다. 작은 부분 하나까지 입문 독자를 위한 배려가 느껴졌다.
문자열 검색 파트도 비교적 자세히 다뤘기에 차후 AI 진영의 NLP를 익힐 때 큰 도움이 될 만큼 기초를 다지는데 도움이 되며, 특히 리스트 부분은 링크드 리스트는 물론 확장 버전별로 매우 상세히 다뤄 처음 접하는 독자들도 쉽게 이해할 수 있게 구성되어 있다.
개인적으로 검색, 정렬, 트리 등의 알고리즘이야 라이브러리가 잘 되어있어 활용에 있어서 만큼은 큰 중요성을 느끼지 못했는데, 리스트의 경우 알아두면 실전에서 사용자 정의 알고리즘에 있어 유사한 형태가 자주 활용되기에 실전적인 알고리즘이라 생각한다. 역시 실전에 도움되는 구성답게 상당한 지면을 할애한다.
마지막으로 트리는 기본적인 종류만 다루고 있어 약간 아쉬움이 남았다. AVL, red-black, B, B+, 2-3 tree 등 다양한 트리가 소개되지 않아 파일 구조나 데이터베이스에 관심이 깊은 독자분들은 다소 부족함을 느낄 수 있다.
더불어 Python의 포인터를 다루는 부분의 설명이 다소 부족하여 포인터 개념에 익숙치 않은 독자들은 관련 부분에 어려움을 느낄 수 있다. 하지만 어디까지나 본 도서는 입문서이므로 입문서 기준으로는 나무랄 부분은 없어 보인다.
전반적으로 책의 장점으로 비추어 볼 때 C나 Java와 같은 다른 언어에 이미 익숙하지만 Python을 처음 접하시는 분들께 매우 유용할 것이라 생각된다.
더불어 알고리즘을 알고는 있지만 아직 명쾌하게 이해하지 못하는 분 또한 본 도서가 큰 도움을 줄 수 있으리라 본다. 알고리즘을 이미 명확하게 숙지하고 있음에도 실전에서 새로운 알고리즘을 개발할 때 방향을 잡기 어렵거나 속도가 나지 않는 분들은 실전 감각을 키우는 데 도움이 될 것이다.
그 외에도 알고리즘을 처음 접하는 분이나 Python을 배우고 싶은 분께도 추천하고 싶다. 어떤 레퍼런스보다도 쉽게 이해하고 실전에 빠르게 적용할 수 있기 때문이다.
