[리뷰] 통계의 아름다움
in Review on Review, Book, 통계, 과학, 수학, 예시, 시각화, 모델링, 빅데이터, 함정, 본질, 선형대수

제이펍출판사의"통계의 아름다움(리찌엔, 하이언 저/김슬기 역/김재광 감수)"를 읽고 작성한 리뷰입니다.
이 책의 최고 장점을 꼽으라면 단연 96가지의 예시들이다. 통계학에 어울리는 귀납적인 예시를 통해 저 위에 추상적으로 존재하는 딱딱하고 어려운 통계의 개념을 96가지나 되는 예제로 비추어 일상의 언어로 끌어내리는 탁월한 가독성과 폭 넓은 저자의 박학다식에 극찬을 아낄 수 없다. 먼저 그 예시들이 무엇인지 몇 가지 소개해 보려 한다.
- 로또 복권 당첨 숫자로 지금까지 1 ~ 20의 숫자가 많이 등장했다면 다음 회차에는 21 ~ 45의 숫자가 많이 등장할까?
물론 “아니다”. 조금만 생각해보면 동전 던지기에서 앞면이 여러번 등장했다고 다음번에 뒷면이 등장할 확률이 높아지는 것은 아님을 알 수 있다. 그런데 왜 가끔 우리는 직관적으로 이런 오답을 내리는 것일까?
정도의 차이가 있을 뿐 우리는 모두 정규분포라는 단어를 알고 있다. 중학교 때 부터 이미 배운 용어이기 때문이다. 그런데도 이 단어가 친숙하지 않은 이유는 무엇일까? 아마도 분포라는 단어보다는 “정규”라는 단어 때문일 것이다. 그런데 정규라는 단어는 정상(Normal)이라는 뜻이다. 한 마디로 정상적인 분포라는 뜻이다. 자연계에는 정규 분포가 더 많이 나타나기에 상식적으로 흔한 쪽에 정상이라는 단어를 부여한 것일 뿐이다.
아래 그림은 책에 등장하는 정규분포와 균등분포의 차이이다. 일상에는 정규분포가 훨씬 많은데 우리의 직관은 균등분포가 당연하다고 착각한다. 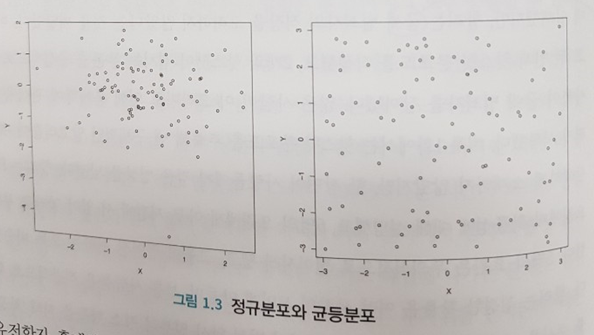
아래 라오의 실험 결과를 보면 정규분포와 균등분포의 착각에 대한 감을 잡기 더 쉬워진다. 단지 3번의 쉬운 조사를 표로 정리한 결과이다.
- 병원에서 1,000명 신생아의 성별(남/여) 기록
- 동전을 1,000번 던져서 앞면/뒷면 기록
- 상상 속에서 동전을 1,000번 던져서 앞면/뒷면 기록
- 마지막으로 각 3개 유형의 기록을 5개씩 모아 앞면 혹은 남자의 등장 횟수를 기록한다.
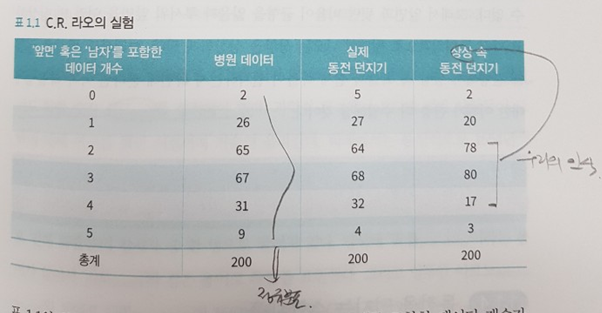
실험1(병원데이터)와 실험2(실제 동전 던지기)는 자연계의 확률 현상으로 지극히 정상적으로 정규 분포를 띄고 있음을 알 수 있다. 그런데 실험3(상상 속 동전 던지기)를 보면 우리의 인식은 판이하게 다르다. 즉, 균등분포에 대한 확률 집착을 떨치기 어려워진다. 앞/뒷면의 비율이 깨질까 염려되어 비슷한 횟수로 앞/뒷면을 맞추고자 노력하기 때문이다.
정규분포의 학문적 정의를 내리기 이전에 이 시각화 자료와 로또 복권의 예시를 먼저 배워야 하지 않을까? 바로 이 책이 지식을 전달하는 방식처럼 통계, 과학, 수학의 개념을 위와 같이 예시, 시각화 자료, 일상의 언어를 통해 먼저 이해를 도와야 한다는 말이다.
책에 등장한 모든 예시들에 대하여 위처럼 발견한 인사이트를 자세히 다뤄보고 싶지만, 리뷰라는 특성 상 영감을 돋궈주는 몇가지 재미있는 예시 및 인용구들을 짧게 나열해 보겠다.
아주 오래전부터 인류는 확률성 사고를 가지고 있었다. 심지어 “역경”의 점치기도 확률 숫자
시드(Seed)를 설정해야 했다.- 상금 배분 문제
- 규칙 : 이긴사람에게 10점을 부여. 60점을 먼저 획득한 사람이 승리.
- 상황 : A가 50점, B가 30점인 상태에서 불가피 하게 게임이 중단될 경우 상금을 어떻게 배분해야 공정할까?
가능성이라는 개념이 등장한다.
- 중국 우한 시민 서민 아파트 공개 추첨
- 우한시 : 5141명 중 124명 당첨. 그 중 6명의 아파트 증명 번호가 연속된 숫자로 드러나 자격 박탈.
- 라우허코우시 : 1138명 중 514명 당첨. 그 중 14명이 연속된 숫자였지만 자격 유지.
- 어떤 차이가 있을까? 여기에서
귀납법 계산과 몬테카를로의 인사이트를 얻을 수 있다.
- 몬티홀 문제
- 3개의 문이 있다. 1개의 문 뒤에는 차(Car), 나머지 2개의 문 뒤에는 염소가 있다. 차를 고르면 상품으로 주어진다.
- 참가자가 하나를 고르면 사회자가 문 뒤에 나머지 하나를 열어 염소를 보여준다.
- 참가자는 문을 고를 기회가 다시 주어지는데 “선택을 유지할지 vs 다른 문을 선택할지”의 상황에서 어떤 선택이 유리할까?
조건부확률과 베이즈 추론을 이해하는데 이만한 예제가 없다.
- 차(茶)를 맛보는 여인
- “차를 먼저 따르고 우유를 나중에 따른다. vs 우유를 먼저 따르고 차를 나중에 따른다.” 중 어느 차가 더 맛있을까?
- 통계 추론에서 매우 중요한
가설 검증, 귀무가설, 유의수준을 쉽게 이해할 수 있다.
- 검은 공의 비율은?
- 상자안에 흰공, 검은공이 전체 N개 있다. 1개를 꺼낸 후 다시 상자에 집어넣는다고 가정하고 10회 반복했을 때 1개가 검은공이라면 상자안 검은공의 비율p는 얼마인가?
최대우도를 이해할 수 있다.
- 식스시그마의 결함률은?
정규분포, 표준편차, 귀무가설을 이해할 수 있다.
- 뉴턴의 사과
- 연역적 : F = G * (m1 * m2) / r^2
- 귀납적 : F = f(m1, m2, r) + e
적합(fitting), 학습, 오차의 이해
- 명목, 서열, 등간, 비율 척도
- 명목척도 : =, != 연산만 가능
- 서열척도 : >, < 연산도 가능
- 등간척도 : +, - 연산도 가능
- 비율척도 : *, / 연산도 가능
- 구차한 설명없이
수학으로 직관적인 설명이 가능하다.
- 제노의 패러독스
- 상황 : 아킬레우스의 속도가 거북이의 10배. 100m 앞에서 도망치는 거북이를 아킬레우스가 잡을 수 없다.
- 이유 : 아킬레우스가 100m 쫓아가면 거북이는 10m 앞서 간다. 다시 아킬레우스가 10m 쫓아가면 거북이는 1m를 앞서 간다. 무한 반복되어 영원히 거북이를 잡지 못한다.
시간의 연속이라는 개념이 등장하며극한과 급수를 이용해 이 오류를 해결할 수 있다.
- 설계행렬(Design Matrix = Data Frame)
- 일반적인
행렬(Matrix = Numpy)와는 다른 개념 - 개체의 관점 : 행이 기본단위
- 분석의 관점 : 열이 기본단위
- 수학적 관점 : 벡터가 기본단위
- 기하학적 관점 : 공간의 표본점(열과 행은 차원)
- 일반적인
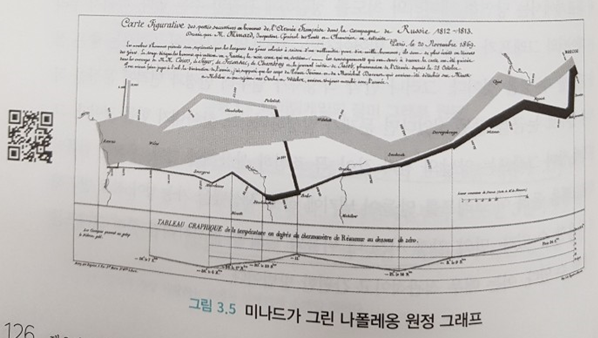
- 시각화와 역사상 가장 좋은 통계 그래프(나폴레옹 원정)
- 시각화의 모든
역사, 발전과정, 극좌표와 직각좌표 간 선형변환등을 알 수 있다.
- 시각화의 모든
머신러닝과 딥러닝의
모델에 관한 대부분의 지식과 직관적 예시통계학에서부터 빅데이터까지의 주요
개념 및 도구들의 변화- 데이터의
함정- 중국 IT 업계의 대부들은 모두 전갈자리 생일을 갖고 있다?
- 승자의 저주 / 여신과의 인연 / 이름의 중요성 / 미국의 대선 / 행운아의 전설 / 하버드 총장의 해고 / 심슨의 패러독스
신의 언어를 인간의 언어로 표현하는 방법 중에 구체적인
예시만한 것이 또 있을까?
소크라테스의 문답법, 성경이나 고대 경전을 보면 직관적으로 이해하기 힘든 난해한 개념을 설명할 때 극단적인 보기를 들어 예시를 들곤 한다.
앞서 언급했듯 통계라는 딱딱하고 난해한 개념을 쉽게 표현하기 위해 이 책에는 정말 많은 예시들이 등장한다. 직접 세보진 않았지만 역자의 머리글을 읽어보면 무려 96가지의 예시가 등장한다고 한다. 통계학을 다루는 서적답게 귀납적인 예시를 통해 통계를 설명하는 구성이 흥미롭다.
책은 그저 예시만 다루는 것이 아니다. 2장 데이터와 수학 편을 보면 선형대수의 메타지식을 물흐르듯 설명하는데 그간 배워온 선형대수 지식에 등고선이 생기며 무엇이 중요하고 파트별로 데이터 분석이나 통계에 어떤 방식으로 활용되는지 입체적으로 이해할 수 있었다. 뒷장에는 현대에 각광받는 머신러닝, 딥러닝은 물론 시각화와 데이터의 함정까지 다루고 있어 추천사에서 읽은 바와 같이 통계학의 고전부터 최신까지 거시적 이론 프레임에 대한 저자의 이해도가 느껴진다.
학창시절 처음 통계라는 말을 들었을 때 느꼈던 이미지를 회상해 보면 “숫자 덩어리, 복잡함, 아저씨, 재미없음” 정도의 느낌이었다. 하지만 그 때 이 책을 만났더라면 난 주저없이 통계학을 전공으로 선택했을 것이다.
지금와서 느끼는 통계는 책의 제목만큼이나 꽤 아름다운 학문이고 진리의 끝에 도달하고 싶어 노력했던 여정의 기록이라는 생각도 든다. 이런 통계의 의미는 늘 곁에 있었지만 내 안목은 좁아 미리 알지 못했고 알파고가 등장한 이후에야 조금이나마 제대로 느낄 수 있었을 뿐이다.
AI, 빅데이터, 4차 산업혁명 거창한 말을 시작하기에 앞서 진정 AI 분야로 발을 들이고 싶은 학생이나 입문자가 있다면 꼭 이 책으로 시작하라는 말을 드리고 싶다. 철학, 과학, 수학, 그리고 저자의 인생이 모두 녹아있어 스스로 이 분야의 적성에 적합한지 검증하는데 도움이 될 것이다. 더불어 통계의 첫 인상을 복잡한 숫자 덩어리로 인식하는 것이 나을지 일상의 흔한 흥미로운 퀴즈로 인식하는 것이 나을지 첫만남, 첫인상을 생각해 본다면 이 책으로 시작하는 것이 얼마나 행운일지 알게 될 것이다.
아울러 이미 데이터 분석, 과학 업무에 종사하는 이들에게도 추천하고 싶다. AI 세계의 무협지처럼 - 실제로 무협지의 예시도 자주 등장한다. - 흥미 진진하여 업무를 중단하고 머리 식히기에 이만큼 재미있는 책을 찾기 힘들 것이며, 통계와 데이터 과학의 세계는 너무나도 광범위하므로 분명 몰랐던 인사이트를 얻어 현재의 실력을 업그레이드 할 수 있는 좋은 인사이트를 제공할 것이기 때문에 필독을 권하는 바이다.
