[리뷰] 파이썬으로 시작하는 캐글
in Review on Review, Book, Kaggle, 캐글, 타이타닉, 실전, Eda, 가설, 머신러닝, 알고리즘, 하이퍼파라미터, 교차검증, 앙상블, 이미지, 텍스트, Lightgbm

제이펍출판사의"파이썬으로 시작하는 캐글(이시하라 쇼타로, 무라타 히데키 저/윤인성 역)"를 읽고 작성한 리뷰입니다.
본 도서는 가급적 최단 시간 내에 Kaggle 경진 대회의 실전을 경험할 수 있도록 구성된 책으로 대회에 필요한 주요 뼈대를 잘 간추린 실전에 초점을 맞춘 책이다.
지금까지 한글로 출간된 캐글 서적은 모두 읽어봤는데 이 책을 포함해서 모두 캐글을 접하기에 좋은 양서들이라는 생각이 든다. 때문에 캐글 경진대회에 참여하기 위한 독자의 수준이 중요한 갈림길이 될 것이라 생각하여 책 소개에 앞서 시간을 아끼고자 가장 적합한 대상 독자층을 먼저 언급하고자 한다.
- Kaggle 경진대회에 한 번도 참여해 보지 않은 분
- 경진대회에 참여해 본 경험이 있으나 Kaggle이 처음인 분
- 그 외 Kaggle 혹은 머신러닝 입문자
위 독자층이라면 이 책이 상당히 좋은 입문서가 될 수 있을거라 생각한다. 코딩을 필요로 하는 실무 대다수가 그렇듯 일단 “백견이 불여일타”가 중요하다고 본다. 아무것도 모를지라도 당장 실전에 돌입하고 코딩해보면 적은 시간만 투입해도 전체적인 윤곽을 익히는데 효율적이기 때문이다. 
이 책은 캐글을 깊이 있게 분석하기 전에 일단 시작하고 본다. 예제는 입문용 대표적 튜토리얼로 손꼽히는 타이타닉 생존율 예측 경진대회로 시작을 한다. 1장에서 짧막한 개요를 설명한 후 바로 Notebooks으로 실습에 들어간다. 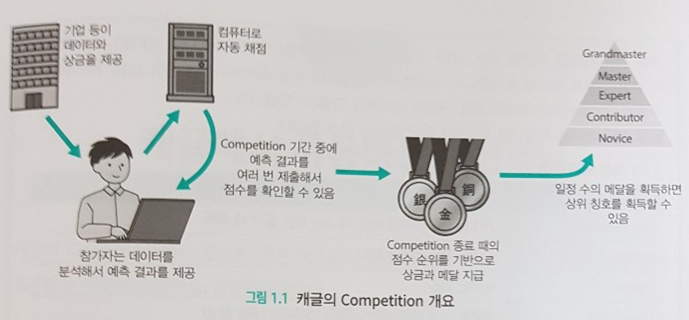
실전 중심의 구성이라 말할 수 있는 또 다른 하나의 증거는 책의 구성이다. 지금까지 접했던 캐글 혹은 다른 경진대회에 관한 책은 실습 코드를 작성하며 Python 문법 혹은 관련 라이브러리, 통계적 지식에 대해 코드 하나 하나 깊이 설명을 하고 넘어가는 구조인데 이 책은 구성이 좀 다르다.
2장에서 캐글 경진대회용 코드를 작성하는 일련의 과정을 쭉 훑어본 후 상세 코드 설명은 맨 마지막 부록에서 상세히 다룬다. 입문자 기준으로는 어쩌면 어떤 기능의 코드인지 명확히 알지 못한채 다음 챕터로 넘어가는 셈인데 덕분에 캐글에 참여하는 전체 메인 흐름이 쉽게 한 눈에 들어온다.
즉, 머신러닝 보다는 캐글의 시스템에 적응하고 모델의 알고리즘을 활용하는 일련의 분석 과정을 빠르게 한 바퀴 도는 것이 목적이기에 먼저 리더보드의 점수를 확인하고 상세 설명에 들어가는 편이다. 캐글에 대해 거의 아는 것이 없는 입문자라면 중간 중간 삼천포에 빠지지 않고 캐글을 빠르게 여행해 볼 수 있는 장점이 인상적인 책이다.
이러한 구성은 개인적으로는 매우 마음에 든다. 다른 분야보다 코딩이 필요한 세계는 구체적이고 명확한 코드가 추상적이고 애매한 개념에 대한 전달의 혼선 가능성을 배제하기 때문이다. 더불어 머신러닝과 데이터 분석 경험이 풍부하나 캐글이 처음인 독자들이 빠르게 익히는데도 효율적인 구성이 될 것이다.
반면 캐글에 이미 익숙하거나 타이타닉 생존율 예측 경진대회 정도는 쉽게 다룰 수 있는 독자라면 이 책을 추천드리고 싶진 않다. 90% 이상은 이미 아는 내용일 것이기 때문이다.
책의 내용을 중요한 파트부터 간단하게 정리해보고자 한다. 우선, 가장 핵심은 2장에 해당하는 부분으로 타이타닉 문제를 해결하며 캐글 데이터 분석 일련의 과정을 익히는 부분이다.
- 예측 결과 submit : Kaggle Notebook / csv 업로드 / Kaggle API
- EDA : Pandas Profiling 활용(Overview, Variables, 피처와 목적변수 간 관계 확인)
- 피처 엔지니어링 : 재현성과 Random Seed, 파생변수 생성
- 알고리즘(모델) : Logistic Regression, LightGBM, RandomForest 활용
- 하이퍼파리미터 : 수동 조정, 튜닝 조정(여기서는 Optuna 사용)
- 교차검증 : 데이터 분포 고려(목적변수, 시계열, 그룹)
- 앙상블 : StratifiedKFold, RandomForest, HoldOut 간 다수결 구조
캐글 경진대회에 한 번이라도 참여한 분들은 알고 있겠지만 정말 캐글에서 필요로 하는 전반을 아주 빠르게 다룬다. 물론 하나의 파트마다 고득점을 위해 대부분 깊게 배워야 하는 부분들이지만 입문자의 입장에서 너무 한 지식에 깊게 빠져 시간을 낭비하거나 방대한 학습량에 주눅들기 보다는 먼저 빠르게 전체 흐름을 이해하는 이 책의 전략은 상당히 좋은 방법이라는 생각이 든다.
나 역시 처음 시작할 때 EDA와 시각화라는 지역최저점(?)에 빠져 전체 일련의 과정을 훑어보기까지 의외로 많은 시간을 낭비했던 기억이 난다.
반면 이 책은 EDA도 Pandas Profiling라는 유용한 라이브러리로 한 눈에 파악하고, 심지어 알고리즘도 바로 LightGBM을 사용하는 돌직구를 던짐으로써 입문자가 빠르게 한 사이클을 도는데 적합하게 구성되어 있다. LightGBM을 활용하며 표준화, 결측치, 카테고리 변수 처리 등의 NeuralNet에서 필수적인 몇가지 전처리 과정을 지나칠 수 있기 때문이다.
그 외 1장은 캐글의 전반적인 시스템과 평가 구조에 대한 개략적인 설명을 다루고, 3장에서는 타이타닉과 같은 튜토리얼 입문용에서 벗어나 새로운 경진대회에 도전할 때 기본적으로 알아야 할 사항을 체크한다. 다중 테이블 간 정규성 확인, 이미지, 텍스트 등이다. 4장에서는 스스로 참여할 캐글 대회를 선정하는 방법이나 분석 환경을 선택하는 방법 등 저자의 경험을 토대로 몇가지 Tip을 알려준다.
저자 중 한 분은 우승 경험이 있는 캐글마스터이고, 다른 한 분은 솔로 금메달 획득 경력이 있는 캐글마스터로 배울 것이 많다. 재미있는 것은 각 장마다 저자들의 이야기 코너가 수록되어 있다. 개인적으로는 책의 내용은 대부분 알고 있는 것들이었기에 캐글마스터들의 경험이 오가는 이 파트가 가장 재미있었고 유용했다. 그 중 인상적이었던 것 몇 가지를 요약해 본다.
- Shake up : Public LB vs CV, Validation의 중요성, 안전-위험 모델 선택 전략
- Tabular 경진대회의 경우 피처 엔지니어링이 승부의 관건이며 도메인 지식도 중요하다. NN을 활용하는 경우 피처엔지니어링 보다는 논문 등의 최신 정보를 얻어 네트워크 구조에 적용하는 것이 중요한 과제이다.
- 데이터를 잘 관찰해서 적절한 처리를 미리 했던 팀들이 상위권을 차지함. 입력 데이터 분포를 예측하여 활용한 조언도 유익했다.
- Notebooks, Discussion의 공개된 정보들만 잘 취합해도 동메달 정도는 딸 수 있다.

이것으로 리뷰를 마치며 캐글을 처음으로 접하는 입문자라면 꼭 읽어볼 것을 추천한다.
