[리뷰] 주머니 속의 머신러닝
in Review on Review, Book, 머신러닝, 주머니, 포켓, Kaggle, Ml, 탐색, 전처리, 피처, 분포, 모델, 파이프라인

제이펍출판사의"주머니 속의 머신러닝(맷 해리슨 저/박찬성 역)"를 읽고 작성한 리뷰입니다.
머신러닝의 자주 활용하는 스킬 80%를 20%의 분량으로 요약한 듯한 느낌을 주는 일종의 머신러닝 사전이다. 마치 국어사전, 영한사전과 같이 필요한 스킬의 가장 중요한 핵심 개념과 활용법을 빠르게 찾아 적용해 볼 수 있으며 컴팩트한 사이즈라 휴대하기도 좋고 새롭게 알게된 주요 기법들을 메모하며 스스로의 실무 지식이나 캐글 등의 경진대회에 활용할 지식들을 단권화하기에도 좋다.
가로 세로 사이즈는 서점에서 볼 수 있는 책 중에서 가장 작은 A4사이즈의 절반도 안된다고 보면 되며 약 300P의 두께로 구성되어 있다. 컴팩트한 사이즈에 머신러닝의 주요 기법들이 거의 대부분 담겨 있는데 예를 들면 “3장. 분류 문제 둘러보기”만 봐도 왠만한 입문서 한 권의 내용이 압축되어 들어가 있다.
목차를 대충 살펴보면 다루는 범위가 얼마나 광범위 한지 알 수 있는데 머신러닝 과정의 개요, 베이스라인, 결측치, EDA, 전처리, 피처 엔지니어링, 평가, XAI, 차원 축소, 클러스터링, 파이프라인의 기법들이 다뤄지고 있으며 특히 활용하는 분류 및 회귀 모델의 알고리즘 대부분이 비교하기 쉽게 잘 정리되어 있다. 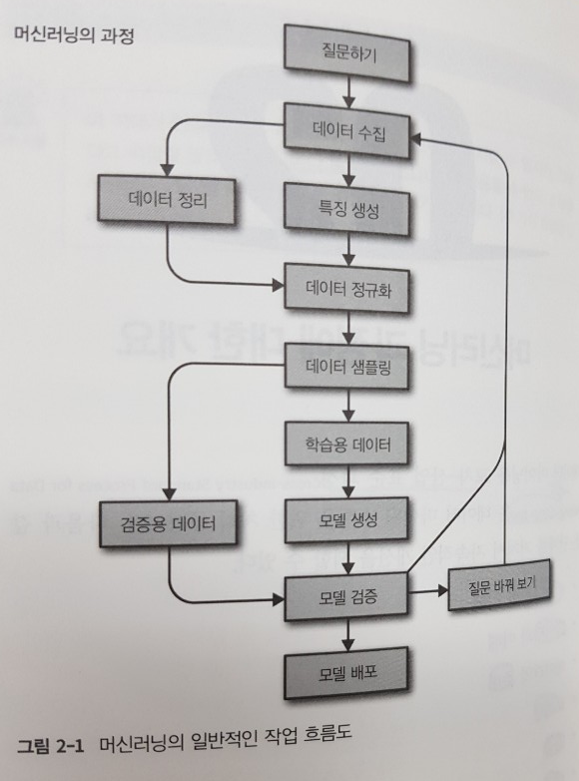
컴팩트한 사이즈에 거의 대부분의 내용을 제법 깊이있게 다루고 있다면 어떤 내용이 생략된 것인지 궁금할 수도 있는데 수학, 연구 수준의 지식은 아주 중요한 것을 제외하고는 포함되어 있지 않다. 더불어 군더더기로 붙는 중요하지 않는 소스코드들은 제거되어 있다. 실무에 초점을 맞춘 구성이라 할 수 있다.
이런 구성상의 특징이 개인적으로는 매우 마음에 들었다. 책을 좋아하는 독자로써 두꺼운 책을 읽으면 읽는 당시에는 잘 이해하고 있을지라도 계속 기억하는데는 한계가 있기 때문이다. 결국 실무를 하며 어차피 책을 들춰보거나, 논문을 찾아본다던가, 수학과 같은 기초가 부족하면 교과서 등을 다시 들춰봐야 한다. 즉, 머리속에 기억하고 있어야 할 가장 핵심만 담고 있어 빠르게 검색하고 활용하기에 좋다.
찾다보면 삼천포에 빠져 너무 깊이 들어가는 경우가 생기는데 문제를 해결하기 위한 탐색인지 개인적인 공부인지 분간하기 어려워진다. 이럴 때 이 책을 이용하면 빠르게 베이스라인을 구성할 수 있을 뿐더러 실무에서의 경험을 잘 메모해 놓는다면 기억이 잘 안날때 들춰보면 빨리 찾아 적용해 볼 수 있어서 유익하다. 두달 여에 걸쳐 실무에 적용해보며 내린 결론이다.
폭 넓은 범위를 다루면서도 핵심 부분이나 혼동되는 부분이 잘 정리되어 있다는 점도 책의 장점 중 하나이다. Python의 유연성은 대부분 큰 장점이지만 때로는 같은 결과를 향한 방법이 다양하게 존재할 수 있어 다른이의 코드를 볼 때 혼동될 수 있다는 단점도 존재한다. 아래 그림의 소스코드와 같이 혼동될 수 있는 부분 또한 잘 정리하고 있다. 
가장 마음에 드는 점은 회귀, 분류에 해당하는 알고리즘을 일목 요연하게 정리한 부분이다. 핵심 코드들이 잘 정리되어 있어 활용한지 오래된 모델의 핵심을 떠올리기에도 좋고 파라미터들이 잘 정리되어 있어 모델별로 기능은 동일한데 다른 명칭을 가진 파라미터를 분간하기에 좋다. 특히 모델마다 시간복잡도를 언급하고 있어 프로젝트마다 주어진 데이터 혹은 가용 자원에 따라 성능 측면에서도 알고리즘을 선택하기 편리하게 구성되어 있다. 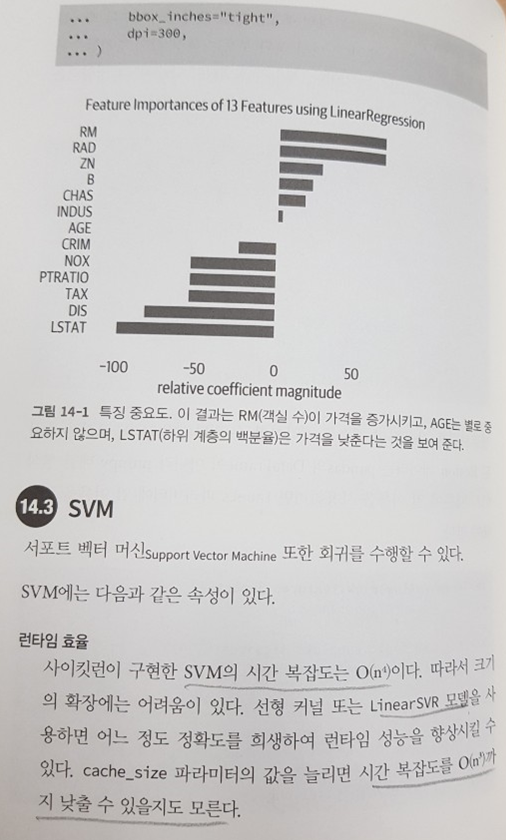
두달 정도 실무에 적용해보며 느낀 점은 머신러닝 프로젝트라는 가정하에 목표로 하는 90%는 이 책 한 권만으로도 모델을 생성하기 충분했다. EDA, 전처리, 피처 엔지니어링은 항상 활용하는 기법들이 거의 다 정리되어 있다. 가끔 특정 기법들이 존재하는지도 기억하지 못한 채 건너뛸 때도 있는데 누락되거나 실수하는 과정이 발생하지 않도록 체크리스트 역할을 톡톡히 해낸다.
앞에서도 언급했듯 두꺼운 책을 읽어봐야 머리 속에 잔존하는 지식은 이 책 정도에 지나지 않는 것 같다. 그런 의미에서 교과서 위주의 두꺼운 책들은 이해될 정도로만 정리해놓고 이 책으로 실전에 돌입하다가 특정 부분에 대해 깊은 이해가 필요할 때 다시 들춰보는 편이 효율적일 것 같다. 즉, 이 책은 머신러닝 서적들의 메타 서적의 개념으로 활용하면 좋다.
머신러닝의 기본 수준을 뗀 독자라면 이 책으로 일단 모델을 구성해 본 후 책에 없는 기법을 활용한 경우 이 책의 여백에 메모를 해 나간다면 추후 훌륭한 본인만의 비급이 탄생하지 않을까 싶다. 다만 입문자나 초보자의 경우 약간 어려울 수 있으므로 먼저 기본서를 통한 실습 후 이 책을 볼 것을 권장한다.
