[리뷰] 파이토치로 배우는 자연어 처리
in Review on Review, Book, Nlp, 자연어처리, Pytorch, 신경망, 임베딩, 시퀀스, 모델링, Attention

한빛미디어출판사의"파이토치로 배우는 자연어 처리(델립 라오, 브라이언 맥머핸 저/박해선 역)"를 읽고 작성한 리뷰입니다.
자연어 처리 입문서로 신경망에서 시퀀스까지의 범위를 다루고 있으며, 각 예제는 Pytorch 1.8 버전으로 구현되어 있다.
개인적으로 동적 계산 그래프 기반의 Pytorch 특성은 정적 프레임워크 언어들에 비해 상대적으로 서비스, 제품 측면에 대한 사전 고민이 필요없기에 프로그래머의 의도를 구현하기 보다 친숙하고 편리하다는 생각이 든다.
지금은 분야 막론하고 Pytorch가 점점 대세 프레임워크로 자리잡고 있지만 초기 등장 시기만해도 NLP 분야에 강세를 보여왔기에 책에서 다루는 주제를 구현하는 프레임워크로 Pytorch가 선택된 점이 마음에 들었다. 또, Pytorch를 다루는 책이 희소하다는 점도 이 책의 가치를 높혀준다.
아래 예제는 퍼셉트론으로 이진 분류를 수행하는 책에서 다루는 가장 간단한 예제인데 Pytorch를 사용한 적이 없는 독자도 이 예제를 본다면 Pytorch의 직관성을 쉽게 파악할 수 있을 것이다. 
책의 특징은 크게 두가지로 요약할 수 있다. 먼저 성능 및 효율성 측면에서 퍼셉트론, 신경망, CNN, 임베딩 단계별로 개선점을 확인할 수 있다. 덕분에 각 단계에서 사용하는 모델이나 스킬들이 어떤 목적으로 활용하는지 감을 잡을 수 있고 베이스라인 코드 감각을 익힐 수 있다. 
또 한가지 특징으로 시퀀스 모델링 파트를 중점적으로 다룬 점을 들 수 있다. 책의 6 ~ 8장에 해당하는 부분으로 먼저 초급 과정에서는 RNN을 적용한다. 국적별로 성씨를 분류하는 모델을 만들며 RNN이 시계열에 적합한 모델임을 확인할 수 있음과 동시에 부분 단어 수준의 단기 기억만 가능하다는 한계점을 파악할 수 있다.
중급 과정에서는 LSTM을 적용하여 단기 기억 문제나 Gradient 소실, 증폭 문제를 해결하는 방법에 대해 다룬다. 특히 200p를 전후하여 게이팅(스위치) 개념을 소개하며 엘만 RNN의 문제를 개선하는 방법에 대한 아이디어가 등장하는데 수식없이 글만으로 이렇게 LSTM의 핵심을 잘 설명하는 책은 드물거라 생각한다.
이렇듯 곳곳에 숨어있는 저자의 전달력, 그리고 밑바닥 예제가 변화하는 과정을 보여주며 특정 개념을 눈으로 확인하며 감을 잡을 수 있게 해주는 구성이 책의 장점이라고 생각한다.
시퀀스 모델 훈련 시 고려할만한 아래와 같은 주요사항들을 정리하며 중급 과정을 마친다.
- 게이트 활용 권장 : 수치 안정성, 단기 기억 문제 해결
- GRU 권장 : LSTM 대비 자원 소모 측면에서 효율적이며 파라미터 수가 적다. (
대부분 LSTM 모델을 대표적으로 설명하기에 이 대목에서 국뽕이 상승하고 뿌듯했다..!) - Adam Optimizer 권장
- Gradient 이상치 클리핑 활용
고급 과정인 8장에서는 Sequence-to-Sequence 모델을 중점으로 학습하며 인코더-디코더 모델을 활용한 조건부 생성 작업도 다룬다. 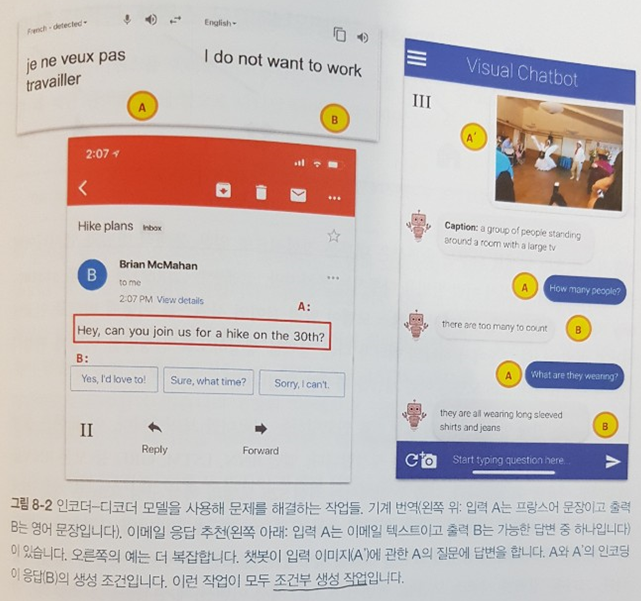
특히 특정 단어를 읽을 때 주변 단어, 절, 장, 주제 등에 주의를 기울이는 사람의 어텐션 매커니즘에서 착안한 Attention 모델에 대해 알아본다. NMT Model과 함께 엔드 투 엔드 기계 번역 예제를 만들 수 있는데 책을 통떨어 가장 재미있는 예제였다고 생각한다.
부록에는 재미있는 주제가 하나 등장한다. 최근 카카오브레인에서 릴리즈한 pororo(뽀로로)의 간단한 개요와 활용 방법을 다룬다. 한글 자연어 처리 작업을 위한 30여 가지의 처리 작업을 선보이는 라이브러리로 책에서는 OCR인식, 이미지 캡셔닝, 번역, 요약, 감성분석, 추론, 토픽 분류 등 7가지 예제를 다뤄볼 수 있다. 관심이 많았지만 시간이 없어 미루고 있었는데 덕분에 pororo의 강력함을 맛볼 수 있었다.

전체적으로 정리해보자면 연구 보다는 구현 및 활용에 초점을 맞춘 책이라고 할 수 있기에 입문서라고 볼 수 있다. NLP에 관심 있거나, 막 입문 단계에 발을 디딘 분이라면 쉽고 빠르게 Sequence 모델의 구현과 실제를 파악할 수 있다.
특히 NLP에 익숙한 독자가 PyTorch의 특성을 빠르게 파악하고 구현 스킬을 올리고 싶다면 이 책에 제 격일 것 같다는 생각이 든다. NLP에 익숙한 분들은 Tensorflow 혹은 다른 프레임워크에도 익숙할 것이기에 빠르게 PyTorch의 패턴을 파악하기에 좋다.
예제와 이론 설명이 따로 노는 것이 아니고 밑바닥 데이터를 예제를 통해 눈으로 확인할 수 있는 구성으로 되어 있어 실전적인 구성이 좋았다.
박해선님의 번역이기에 읽기에 어색하거나 이해되지 않는 부분도 거의 없으며 책의 200p 하단 주석과 같이 재미있는 주석도 볼 수 있다. 보다 자세한 설명은 핸즈온 머신러닝 서적을 참고하라고 언급되어 있는데 역자분이 워낙 많은 책을 번역하시다보니 이런 시너지도 가능해 진다는 것이 재미있고 신선하게 다가왔다.
반면 책에 다소 아쉬운 점도 꼽아보겠다. 사실 단점이라기 보다는 개인 취향인데 책 전반부에 Perceptron, 피드포워드신경망, CNN을 차례차례 도입해가며 성능을 향상 시키는 구성은 마음에 들었으나 이 과정을 하나의 예제로 진행했다면 보다 단계별로 개선되는 부분이 뚜렸하게 드러나 이해에 도움을 주지 않았을까 싶다.
또 어느책이든 마찬가지이지만 기술 서적의 난이도를 잘 알고 책을 구매하는 것은 중요한 부분이라고 본다. 난이도에 따라 대상 독자층이 보기에 충분히 훌륭한 책도 있는데 가끔 난이도 높은 책이 아니라는 이유로 또는 반대의 이유로 오평을 하는 독자들을 자주 봐왔기 때문이다.
그런점에서 나는 이 책 보다는 수준이 약간 높은 편이기에 아무래도 수식이나 연구 결과에 대한 설명이 부족한 부분이나 시퀀스 모델 이후의 부분에 집중하지 않는 것은 약간 아쉬운 부분이다.
저자의 전달력이 굉장히 마음에 들었는데 그 전달력으로 어려운 어텐션 이후 GPT-2, 3와 같은 모델에 대한 설명이 있었으면 더욱 만족스러웠을 것이다. 또 연습문제가 1장에만 등장하고 다른 장에는 등장하지 않는 점도 약간 실망한 부분이다.
하지만 이런 아쉬운 부분들은 개인적인 관점에 따른 부분이고 트레이드 오프를 피할 수 없는 부분이기에 대세에 지장을 주는 단점은 거의 없다고 볼 수 있으며, 특히 입문자에게는 정말 좋은 책이 될 것이라 생각하며 리뷰를 마친다.
한빛미디어 “나는 리뷰어다” 활동을 위해서 책을 제공받아 작성된 서평입니다.
