[리뷰] 가볍게 떠먹는 데이터 분석 프로젝트
in Review on Review, Book, 데이터, 분석, 프로젝트, 케이스스터디, 6단계, 취득, 검증, 전처리, 분석, 시각화, 대시보드

제이펍출판사의"가볍게 떠먹는 데이터 분석 프로젝트(윤영진, 황재진 저)"를 읽고 작성한 리뷰입니다.
데이터 분석과 관련된 실무 프로젝트를 진행하기 위한 방법론과 실제 케이스를 다룬 책이다.
이 책은 분석과 관련된 기술이나 알고리즘을 다루기 보다는 분석과 관련된 실무 프로젝트를 원할히 수행하기 위한 가이드로써 데이터 과학자보다는 실무 프로젝트 총괄 책임자, PM, 팀장, 기획자, CEO에게 적합한 책이다.
국내외에서 주로 활용되는 데이터 분석 방법론 중 하나인 CRISP-DM 표준 방법론을 중심으로 이론을 펼치되 이를 최대한 쉽게 이해할 수 있도록 구성한 것이 특징이며 마지막장에서 케이스 스터디 2가지 사례를 다루고 있어 데이터 분석 경험이 적은 초보자가 이해하기에도 적합한 책이다.
책에서 제시하는 데이터 분석의 뼈대는 6단계로 구성된다. 아래 그림과 같이 목표를 이해하고 이를 기반으로 한 계획을 수립한 후 수집 및 전처리를 진행한다. 이어 본격적인 분석에 돌입한 후 결과를 검증하며 시각화를 통해 의사결정과 당초 목표에 대한 솔루션을 제시하는 것이 큰 흐름이다. 
비유하자면 프로그래밍에 S/W공학론이 존재하듯 데이터 분석계의 S/W공학론 같은 느낌이다. 전적으로 프로젝트를 원할히 운영할 수 있는 전체 그림을 제시하는 것이 책의 차별화된 부분이며 각 단계의 세부 업무 수행은 데이터 사이언티스트나 엔지니어 혹은 분석가들이 수행하게 될텐데 이를 위한 알고리즘 수준의 기술은 극히 일부를 제외하고는 다루지 않는다.
AI, 알파고가 이슈가 된 이후 이 분야에 뛰어드는 사람들은 주로 딥러닝의 성능개선 혹은 알고리즘 기술이나 적어도 머신러닝의 알고리즘에 집중하는 경향이 많은데 어쨌든 이런 기술 또한 수익 혹은 가치 창출과 연결되어야 할 피치 못할 숙명에 처해있기에 프로젝트를 진행하지 않을 수 없다. 이는 이 책이 필요한 이유이기도 하다.
책은 전반적으로 앞서 소개한 6단계의 구성을 차례차례 짚어 나간다. 전체적인 큰 흐름은 2장에 자세히 소개되어 있으며 1장은 주로 데이터 분석의 필요성과 개요를 다루고 있으므로 가볍게 읽으면 된다.
본격적인 내용은 3장부터 진행되는데 데이터 수집 혹은 취득을 다루는 것으로 시작한다. 책을 읽으며 데이터의 수집처가 생각보다 매우 다양하다는 것을 알게 되었다.
내부 데이터 출처원으로는 사내 ERP, CRM, POS, 문서, 기타 애플리케이션이 해당된다. 외부데이터로는 SNS, 공공 데이터, 포털데이터 등 매우 다양한 데이터 출처원이 존재한다. 책에서 이런 부분들이 꼼꼼하게 잘 정리되어 있어 실무 프로젝트에 있어 단계별 누락요소는 없는지 체크리스트로 활용해도 괜찮겠다는 생각이 들었다. 
4장에서는 검증 및 전처리를 다룬다. 데이터의 유형별 모든 검증을 다루고 있진 않지만 적어도 Tabular 성격의 데이터에서 빈번하게 활용되는 검증 방법을 꽤 자세하게 다루고 있다. 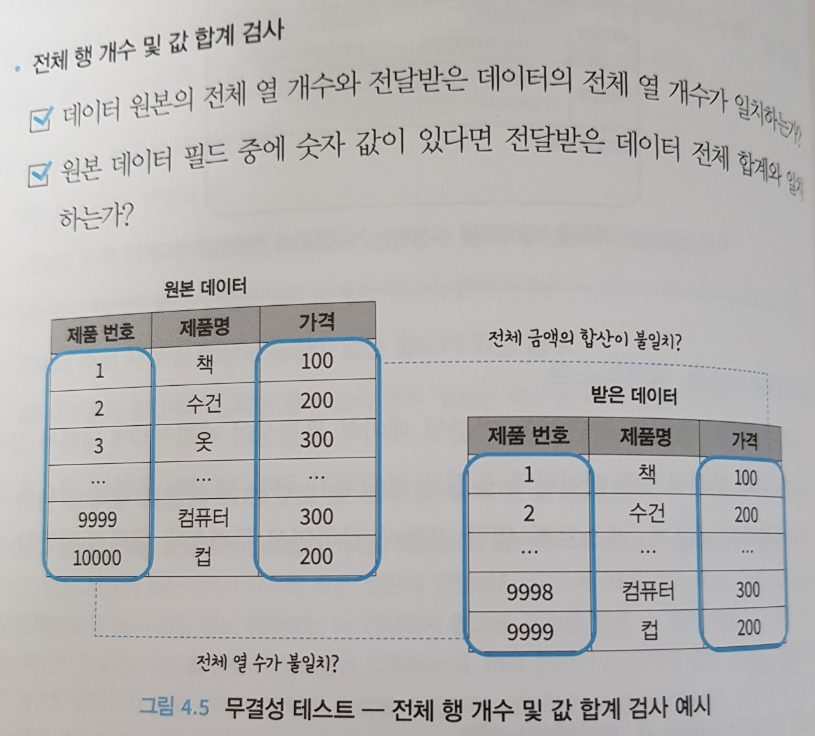
이어 전처리로 이상치, 결측치에 대한 처리 방법이 나오는데 적어도 빈번히 활용되는 MCAR, MAR, NMAR 등의 통계적 데이터 성격에 따른 결측치 처리 방법도 소개되고 있어 기본은 잘 갖추고 있다 판단된다.
5장은 데이터 분석을 위한 10가지 분석도구의 특징 및 장단점을 소개한다. 엑셀을 시작으로 가장 핫한 R, Python 등 그 외에도 태블로와 같은 BI 도구들도 다룬다. 다만 분석 기법이나 알고리즘에 관한 설명은 생략되어 있어 조금 아쉽기도 하다. 철저히 프로젝트와 관련된 거시적 흐름에 집중하는 구성이다.
6장은 시각화를 다룬다. 특히 시각화 시 실무에서 유의해야 할 유형과 함정에 대해 잘 정리되어 있다. 시각화 전체를 다루고 있는 것은 아니지만 적어도 가장 중요한 부분들이 잘 정리되어 있어 이 책에서 다루는 내용만 잘 이해해도 파레토 법칙의 80%는 달성할 수 있다고 본다. 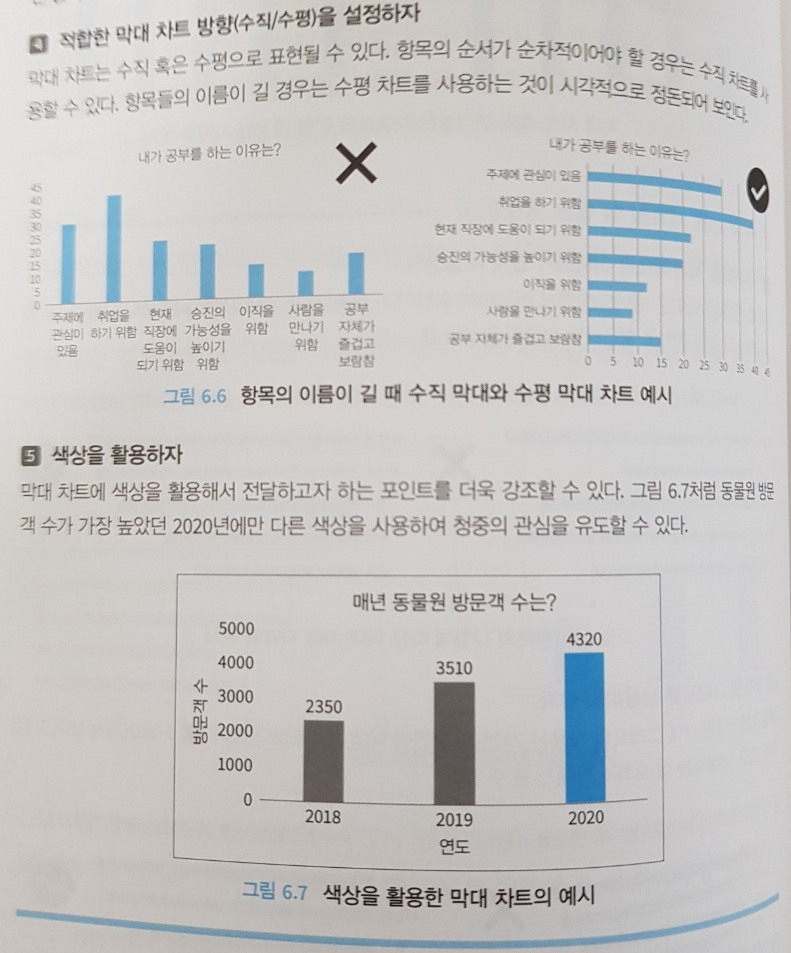
7장은 대시보드를 구성하는 전략이 소개된다. 전략적, 분석, 운영 대시보드별 특징이 소개되고 사내에서 중요시 여겨지는 지표 등을 직관적으로 파악하기에 어떤 대시보드의 구성을 가져가는 것이 좋을지 방법이 소개된다.
마지막 8장과 9장에서는 케이스스터디로 실무 분석 사례를 다룬다. 8장은 서울시 버스 승하차 인원을 분석하여 교통 혼잡 비용을 줄이려는 프로젝트로 매우 기초적인 엑셀을 통한 기술 통계 위주의 분석을 다루고 있다.
매우 기초적인 내용이기에 분석이 묘를 얻기는 어렵지만 대학 학부 수준의 프로젝트에 적용해보고 분석 프로젝트의 큰 흐름을 잡기에는 나쁘지 않은 입문 예제로 보인다.
9장은 온라인 쇼핑몰의 블랙컨슈머를 파악하기 위한 분석을 시도하는데 8장보다는 약간 난이도가 있다. 시나리오나 가설이 등장하며 SQL을 도구로 활용하고 이를 검증하는 절차도 있다.
하지만 역시 매우 기초적인 수준이다. 적어도 통계적으로 분포를 다루는 문제나 귀무 가설 정도 다루는 예제가 추가로 소개되었다면 더욱 좋겠다는 생각이 들었다. 혹은 머신러닝 기법으로 추론, 예측을 진행하는 프로젝트가 같이 소개되었다면 유익했을텐데 독자층을 철저히 입문 수준으로 제한한 것 같다.
어쨌든 이 책은 데이터 분석 프로젝트를 처음으로 임하는 이에게 가장 적합한 책이라는 생각이 든다. 또, 깊숙한 실무를 진행할 필요가 없는 기획자나 총괄 책임자가 프로젝트의 큰 흐름을 빠르게 이해하고자 할 때 좋은 가이드가 될 것이다.
