[리뷰] 나이스한 데이터 분석
in Review on Review, Book, 데이터, 분석, 과학, 트렌드, 음식, 상권, 주류, 자동차, 학군, 실전, 운영, 인사이트, Pos, 매출, 카드

이콘출판사의"나이스한 데이터 분석(나이스지니데이타 저)"를 읽고 작성한 리뷰입니다.
나이스 그룹의 데이터 사업을 담당하는 전문가들의 데이터를 통한 트렌드 분석서이자 실제 데이터 기업에서 수행하는 업무를 정리한 책이다.
책은 크게 두 부분으로 나뉘는데 1부의 핵심키워드는 트렌드와 데이터 리터러시이다.
코로나 이후의 집콕 트렌드에 대한 분석, 주류 수요 분석, 레트로 트렌드 분석, 수입차 구매 예측 지역 분석, 학군 분석 등 일반인들이 개인적으로나 비즈니스적으로나 가장 관심있어 할만한 주제들을 분석하고 있어 재미있게 읽을 수 있다.
이미 분석한 결과를 편히 읽을 수 있지만 읽는 것 만으로는 비즈니스적 지식을 얻는 것외에 특별히 얻을 것이 없다. 이 파트를 보다 의미있게 읽고 싶다면 저자들이 트렌드를 분석하는 과정에서 활용한 데이터 분석 방법과 그 과정을 잘 이해하고 인사이트를 도출할 수 있는 스스로의 데이터 리터러시를 키우는 일이 필요하다.
크게 눈에 띄는 장은 집콕을 분석한 1장과 수입차 수요를 분석한 4장이다. 1장은 데이터 리터러시에 관하여 문외한일지라도 쉽게 읽을 수 있다. 게다가 코로나 후 일상은 누구에게나 자신의 일이 되어 버렸기에 더 공감하며 읽을 수 있을 것이다. 데이터로 대충 이런 분석이 가능하구나 감을 잡고 쉽게 첫발을 딛게 도와주는 장이다.
가장 수준 높은 분석이 이뤄지는 장은 4장이다. 데이터 분석이나 통계에 대한 지식이 있는 사람은 아래 그림을 쉽게 해석할 수 있겠지만 데이터 문외한은 생각보다 어려운 그림이다. 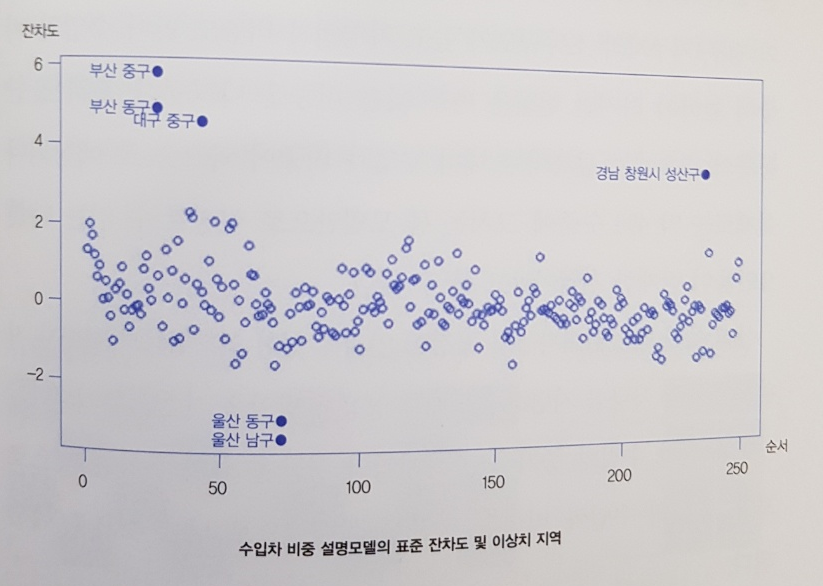
아래식은 수입차 구매 수요를 파악하기 위한 회귀식으로 소득이나 지역 등 여러 독립변수를 기반으로 수입차 구매라는 종속변수를 도출하는 과정에서 이상치를 추출하는 모습이다.
중앙의 은하수와 같은 선을 제외하면 부산 중구를 시작으로 아해 울산 남구에 이르기까지 외딴 섬 마냥 따로노는 데이터가 있는데 이런 데이터를 이상치라고 한다.
예를 들면 울산 동구, 남구의 경우 현대자동차가 있는 지역이므로 수입차 보다 국산차를 더 저렴하게 구입할 수 있기에 수입차 구매량이 적다는 인사이트를 도출할 수 있는셈이다.
이상치는 때로는 전체 트렌트를 분석하고자 버려지는 쓰레기 취급을 받을 때도 있지만 위 사례와 같이 의미있는 통찰을 전해주기도 하기에 처리하는데 주의가 필요하다. 4장은 이런 약간 고난이도의 분석 방법을 다루고 있어 데이터 과학이나 분석에 관심있는 독자들이 다음단계로 넘어가기 위한 징검다리로 괜찮은 장이라는 생각을 했다.
이어서 2부의 내용을 소개하고자 한다. 2부는 데이터 분석 부서에서 실제 어떤 일을 하고 있는지에 대해 다루는 장이다. 1부가 일반인들에게 도움이 되는 데이터 리터러시 수준의 분석을 다뤘다면 2부는 데이터 분석 회사로의 이직 혹은 취업을 목표로 하는 독자들에게 도움이 될 것이다.
6장은 데이터 분석을 위한 기본적인 개념을 총체적으로 잘 정리하고 있다. 군집분석, 연관분석, 시각화의 중요성과 의미 등 일반적인 데이터 분석팀에서 밥먹듯이 수행하는 일들이 대충 어떤 일들인지 포괄적으로 잘 정리하고 있다.
7장은 데이터 엔지니어링 및 인프라 업무를 잘 정리하고 있다. 아래 그림과 같이 데이터는 분석이나 모델링으로 끝나는 것이 아니다. 알고리즘이나 모델이 가설을 잘 검증하기 위해 데이터를 수집, 정제, 전처리 하여 알기 쉽게 떠먹여줘야 함은 물론 그 결과를 서빙하여 제품으로 만들어 낼 줄도 알아야 한다. 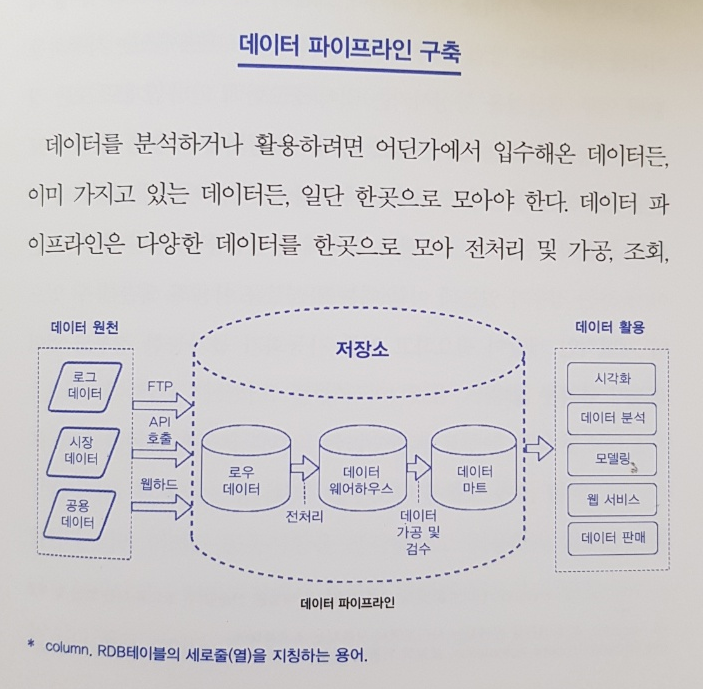
이를 위한 총체적인 파이프라인 과정이 필요한데 각 과정의 세부 유닛들을 잘 정리하여 설명하고 있다.
8장에는 그 외 데이터 특성을 다룬다. 데이터 분석의 80%는 전처리라는 근거 없는 낭설을 주위에서 많이 듣곤 하는데 그만큼 전처리는 많은 시간을 잡아먹는 귀찮은 일임에는 이견의 여지가 없다.
아래 그림은 전처리가 무엇인지 가장 구체적으로 잘 설명해주는 그림이라 할 수 있다. 현실의 데이터는 위 테이블이고 이를 전처리를 거쳐 정제한 데이터는 아래 테이블이라 생각하면 된다. 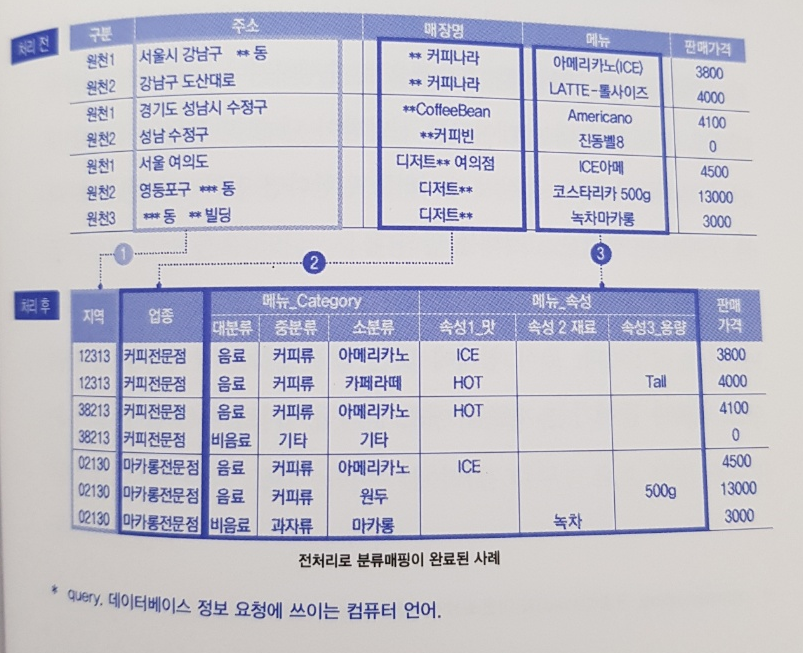
조금 더 자세히 들여다보면 주소는 도로명주소 우편번호로 정제하고 있고, 매장명은 업종으로, 메뉴는 어떤 분류에 속하는지 속성은 차가운지 뜨거운지 용량은 어떤지 등등의 세부 데이터로 분류된다. 그나마 판매가격은 숫자 데이터인지라 전처리 과정을 거칠일이 적다.
이 한 그림만 제대로 이해하고 있어도 전처리에 대한 대부분의 설명이 가능한데 이 책에서 좋은 예시를 담고 있다는 생각이 들었다. 2부에서 현장의 실무를 담기 위해 애썼다는 저자들의 소개에 공감할 수 있는 부분이었다.
마지막으로 9장에는 CEO를 위한 조언이 담겨 있다. 데이터 비즈니스를 꿈꾸는 이들은 무엇을, 어떻게가 아닌 왜라는 질문에 답할 수 있어야 함을 강조한다. 특히 3VD 과정을 통해 현재 보유하고 있는 데이터가 얼마나 더러운지 평가하는 방법이 소개되는데 꽤 도움이 될만한 사항이라 생각했다.
각각 얼마나 지저분하고 귀찮은 과정을 거쳐야 하는지, 얼마나 전문적이고 어려운 성격의 데이터인지, 분석할수록 위험해지며 법적 분석 검토가 필요해지는 데이터들이 3VD에 해당하는 데이터라 할 수 있다. 관련 세부 체크리스트가 제시되어 있어 실질적인 도움이 될 것이다.
정리하면 이 책은 일반인이 데이터 문해력에 관심이 있거나 기본적인 통계, 데이터 과학을 학습한 이들이 커리어를 위한 도전을 위해 입문 과정으로 읽을만한 도서이다. 저자들이 상당히 정성을 기울여 독자들이 잘 소화할 수 있게 떠 먹여주는 느낌이 들었다.
반면 개인적으로 한 가지 아쉬운 점은 실전에서 정확히 어떤 일을 하는지 매우 디테일한 예를 들면 신입 사원이 직접 나이스 데이터에 취업하여 겪는 일들 그러니까 조금 더 거친 실무 내용이 등장하길 바랬는데 보다 추상적이었다는 생각이 들어 아쉽다.
어쩌면 이런 거친 데이터와 일을 다루면 책이 전혀 안 팔릴지 모르겠다. 이는 내 취향이므로 책을 평가하는데에는 불필요한 요소이지만 그래도 요즈음은 일반적인 분석 방법론을 다루는 책이 포화상태인지라 나와 같은 생각을 갖고 있는 독자 수요층이 꽤 있진 않을런지 생각해본다.
