[리뷰] 파이썬을 활용한 금융 분석 (2판)
in Review on Review, Book, 금융분석, 파이썬, 데이터분석, 시각화, 시계열, 확률, 통계, 트레이딩, 매매전략, 파생상품, 자동화, 포트폴리오, 가치평가, 프레임워크

한빛미디어출판사의"파이썬을 활용한 금융 분석(이브 힐피시 저/김도형 역)"를 읽고 작성한 리뷰입니다.
금융 데이터 분석에 Python을 어떻게 활용할 수 있는지 정리한 기술서로 확률 과정과 통계 분석 등 데이터 과학에 필요한 지식을 습득할 수 있으며 나아가 알고리즘 트레이딩과 파생상품 분석의 기초를 다루고 있다.
Python 스킬과 금융 공학이라는 두마리 토끼를 잡을 수 있는 책이다.
보통 두가지 주제를 한 번에 다루다 보면 어느 한 쪽을 깊이 다룰 수 없는 트레이드 오프가 발생하기 마련인데 대략 800페지이에 달하는 분량과 5개 파트, 21개 챕터에 이르는 방대한 양의 내용이 어느정도 트레이드 오프의 단점을 상쇄하고 있었다.
파트는 5개이지만 크게 세부분의 내용으로 압축할 수 있다.
파트1, 2의 내용은 Python 스킬을 키우는데 집중한다. 파트3는 Python과 금융공학의 교집합에 해당하는데 금융 공학으로 넘어가기 전 데이터 과학을 다룬다. 마지막으로 파트4,5는 알고리즘 트레이딩과 파생상품을 분석하고 있어 금융공학 입문을 맛볼 수 있다.
먼저 파트1, 2를 소개하자면 금융 데이터 분석에 초점을 맞춰 도메인 영역을 한정짓고 다른 언어 대비 Python만의 독특한 기능을 중심으로 간명하게 정리하고 있기에 읽기 편하고 빠르게 핵심에 집중할 수 있다는 것이 장점이라는 생각이 들었다.
51 ~ 52p에 걸친 코드 예제는 Python이 얼마나 유연하고 다양한 기능을 갖추었는지 보여주는 대표적인 예제이다. 
일반적인 방법으로 Python 코드를 구현한 실행 시간은 1.6초이다. 이어 Numpy 라이브러리 Vectorization을 활용한 결과가 88밀리초로 줄어듬을 보여준다. numexpr을 활용하여 50밀리초로 성능을 개선한 후 멀티스레드를 활용하여 23밀리초로 실행 속도를 향상시킨다.
알고리즘이나 업무도메인 지식없이 Python 자체 제공 기능만으로 이런 성능 개선이 가능하다는 점은 Python 라이브러리가 제공하는 기능이 얼마나 다양한지 보여주는 단례이자 유연성과 고성능에 대한 생태계의 노력을 보여주는 한 단면이다.
이어서 로그수익률이나 SVM과 같은 간단한 머신러닝 알고리즘을 적용한 예제를 구현하는 실습이 이어지는데 Python이 금융 분석에 어떻게 활용될 수 있는지 빠르게 감을 잡기에 좋게 구성되어 있다.
Conda, Docker, Droplet 클라우드 서비스로 단 몇 분 만에 금융 데이터 분석 인프라를 구성할 수 있음을 보여줌으로써 앞으로 이어질 실습환경을 빠르게 구성할 수 있음은 물론 Python이 왜 금융 데이터 분석에 최적화되어있는지 간명하게 소개하고 있다.
파트2에는 Python만의 독특한 문법과 기능이 소개된다. 특히 다른 언어에 익숙하나 Python이 처음인 프로그래머들이 적응하기 좋게 구성되어 있다.
for문과 같은 루프문에서 별도의 카운터 변수 - for문을 돌며 몇번째 루프인지 파악하는 용도의 숫자 변수 - 를 활용하지 않고 리스트 객체를 활용하는 것은 Python 세계로 처음 넘어온 프로그래머들의 첫번째 생소함인데 이를 빼놓지 않고 언급하고 있다.
table, list, dict, set과 같은 다른 언어에 내장되지 않은 자료구조를 소개한 점도 맥락이 동일하다. 부동소수점 정밀도와 관련된 의도하지 않은 계산 결과, 문자열과 format, re 정규표현식 라이브러리 등 Python만의 독특한 점이 잘 소개되어 있다.
다른 언어 대비 절대 강점을 가지는 Numpy, Pandas 라이브러리는 각각 하나의 챕터를 활용하여 깊이있게 다루고 있으며 파트의 마지막 장에서 객체지향을 알아봄으로써 타 언어 대비 Python의 차이점을 최종적으로 정리해 볼 수 있다.
파트3는 데이터 과학을 다루는 장이다. 상대적으로 익히기 쉽고 직관적으로 빠른 이해가 가능한 시각화 파트를 먼저 다루고 있어 독자의 부담을 줄여준다. 특히 무분별한 시각화가 아닌 도메인이 금융 분야로 한정되어 있다. 덕분에 RSI와 같은 주식 지표를 시각화하는 방법을 쉽게 습득할 수 있었다. 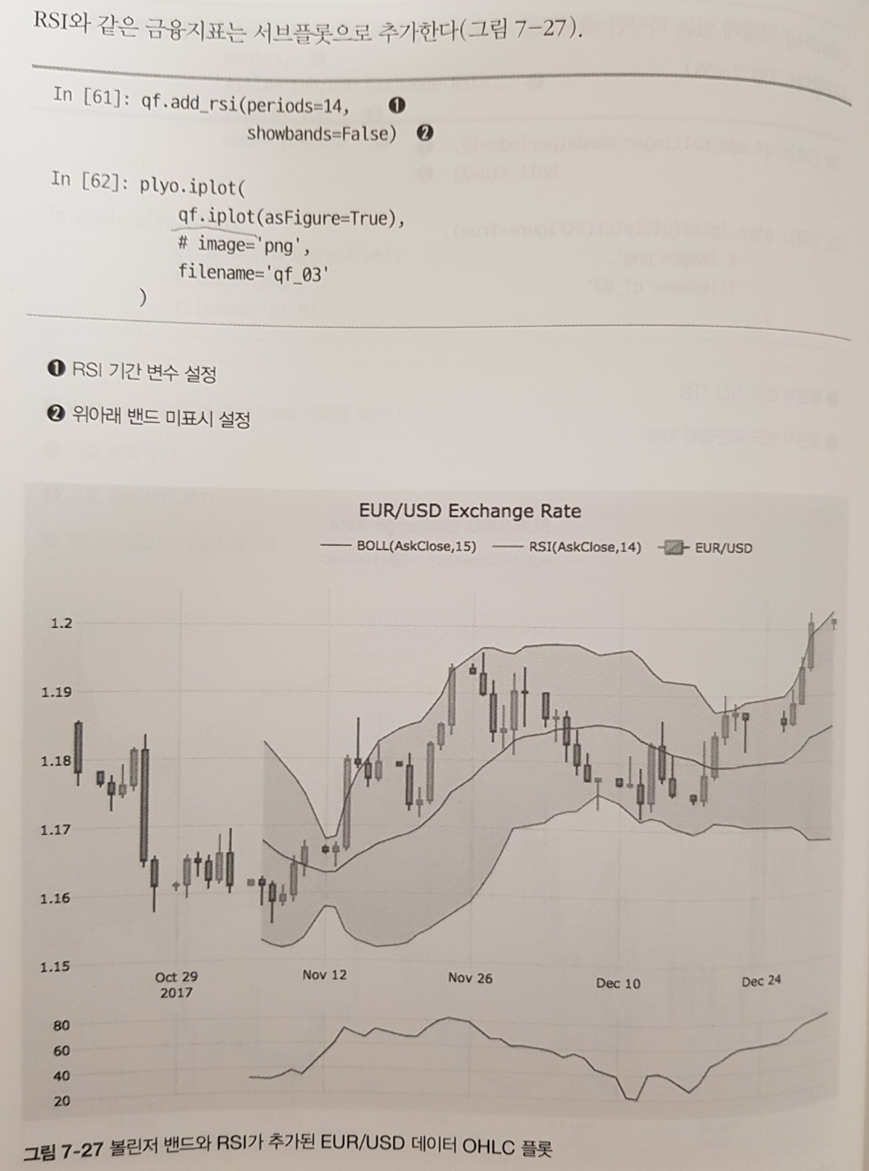
시각화 부분을 1차원, 2차원, 정적3차원, 상호 2차원 등의 분류로 적절히 잘 나누고 있어 향후 각 aixs나 색상 등의 속성에 어떤 값을 연결해야 하는지 초보자가 직관적으로 이해할 수 있도록 분류한 구성이 마음에 들었다.
Pandas와 시계열을 잘 조합하여 설명한 부분도 마음에 들었다. 특히 금융분석은 시계열 그 자체이므로 Dataframe의 rolling 등의 기능에 능숙해져야 하는데 시계열을 중심으로 기능을 집중적으로 설명하고 있어 금융 분석에 도움이 될 수 있는 괜찮은 학습서라는 생각이 들었다.
다양한 포맷의 I/O 또한 데이터 분석을 어렵게 만드는 장애물 중 하나인데 HDF5, Pickle 직렬화, SQL, Numpy, file, csv, Pytables 등 어떠한 형태의 데이터일지라도 DB, File 가리지 않고 쉽고 빠르게 저장, 발췌를 가능하게 할 수 있도록 통합적으로 기술을 잘 정리하고 있다. 특히 out-of-memory 연산을 지원하는 TsTables이 소개되어 있어 더욱 마음에 들었다.
이어 다른 프로그래밍에서 다루는 자료구조 대비 한 차원 뛰어넘은 데이터 과학에서 자주 활용되는 독특한 자료구조를 알아본다. 원주율, 이항트리, 몬테카를로 시뮬레이션 등의 표현을 훈련하며 수학에서 활용하는 회귀법, 보간법, 최적화 내지 미적분을 Python으로 구현하는 방법을 습득하여 데이터 과학에 한걸음 더 접근해 나간다.
파트의 마지막은 12장의 확률 과정과 13장의 통계분석이 소개되는데 개인적으로 이 책에서 가장 마음에 든 부분이다.
전통적인 금융 공학 기법에서 닫힌 공식을 유도하기 위해 노력했던 것에서 탈피하여 확률 과정을 통한 몬테카를로 시뮬레이션이 유행하게 된 패러다임의 변화를 잘 소개하고 있으며 어려운 확률 분포들을 잘 정리하고 있었다.
파트 4,5에서 어이서 학습하게 될 기초 지식인 기하 브라운 운동 모형, 유러피안 옵션, 확률적 변동성 모형, 블랙-숄즈-머튼 모형 등의 기초 금융공학을 확률 과정과 잘 조화하여 소개하고 있다.
통계 분석에서는 정규성 검정, 프트폴리오 검정, 베이즈통계학, 머신러닝 등의 주제를 다룬다. 그동안 쉬운 데이터를 예제로 삼아 Q-Q 플롯을 그려는 봤어도 언제 실용적으로 써먹을 수 있는지 접할 기회가 적었는데 책이 금융 분야의 도메인을 다루다 보니 보다 실무적으로 깊이있는 활용 방법을 알 수 있어 유익했다.
아래 그림은 수익률이 정규분포를 따른다는 것을 가정한 후 가정이 맞는지 확인하는 정규성 검정의 예이다. 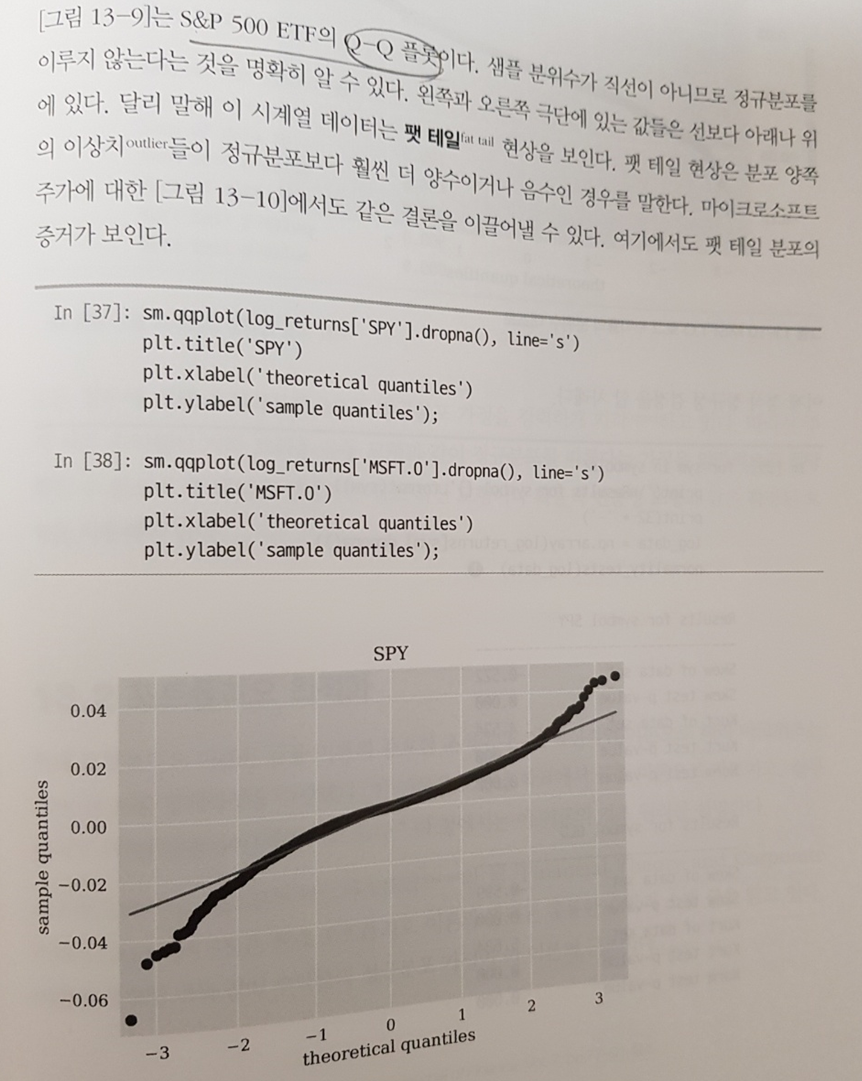
파트4부터는 본격적인 금융 공학을 다루기 시작한다. 알고리즘 트레이딩 파트는 FXCM이라는 프레임워크를 활용하여 일봉, 월봉 등의 정보를 가져와 기본적인 시세 차트를 만들어 본다든가 이평선, 선형회귀, 기본적인 머신러닝 방향성 예측 등을 활용하여 매매를 체결하는 API 호출 실습 등을 진행한다.
특히 16장은 시장의 방향을 예측한 전략을 배포하는 방법이나 자금 관리, 위험 평가를 위한 벡테스팅, 로깅 등의 일련의 과정이 잘 정리되어 있어 마음에 드는 구성이었다.
하지만 전반적으로 심도 깊은 알고리즘 트레이딩 기법이 소개되지 않아 약간은 아쉬웠다. 실제 현업에서 퀀트가 전략을 어떤 식으로 발굴하는지 이를 어떻게 구현하며 확장성 있는 시스템으로 흡수되는지 일련의 과정이 포함되어 있었다면 그래서 독자가 자신의 아이디어를 시스템화 할 수 있도록 친절하고 상세히 안내되어 있었다면 이 책은 더욱 뛰어난 양서가 되었을 것 같다는 생각이 든다.
파트5에서는 금융 공학의 큰 뿌리를 구성하는 파생상품 분석을 다룬다. 먼저 기본적인 가치 평가 프레임워크 DX를 설명하고 금융 모형을 시뮬레이션하는 방법을 소개한다.
특히 기하 브라운 운동, 점프 확산 모형, 제곱근 확산 모형 등을 하나씩 구현하고 적용 결과를 눈으로 확인하면서 금융 공학의 기초가 무엇인지 조금이나마 이해할 수 있어 유익했다. 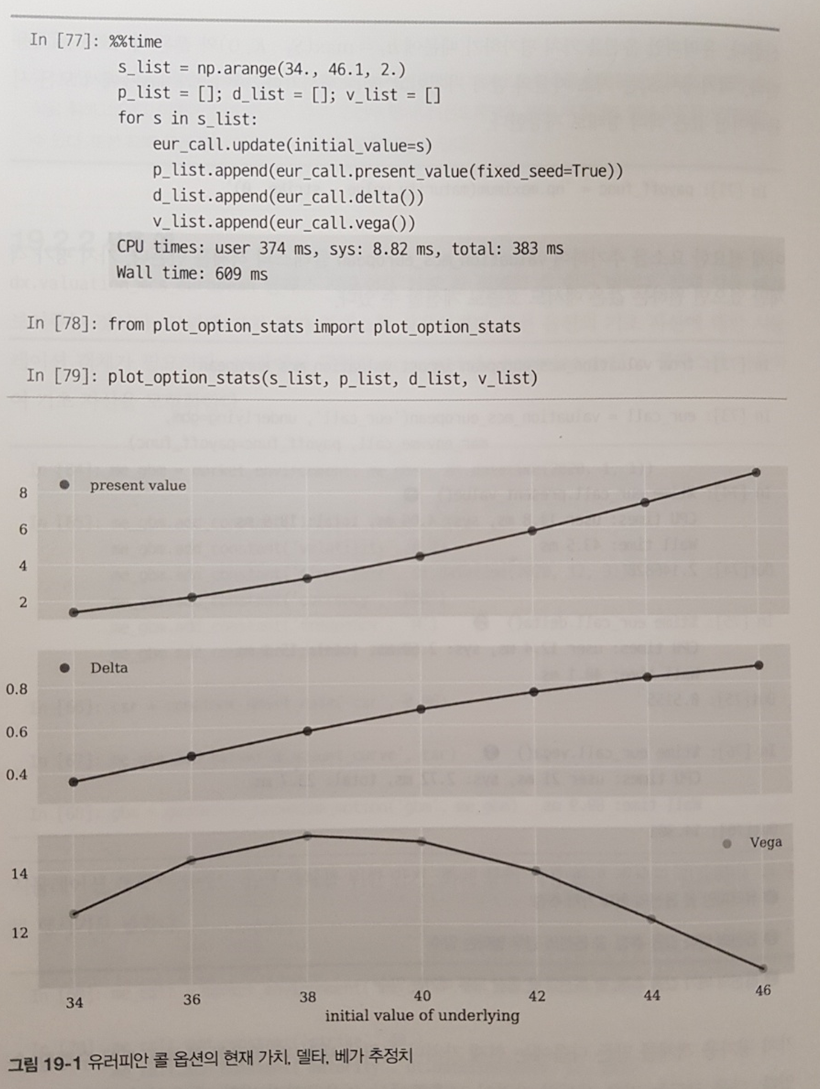
이어서 파생상품, 포트폴리오, 시장 기반 등의 가치 평가 방법도 하나씩 소개되고 있는데 금융 공학에서 다루는 기초 입문 과정을 주제별로 구현해보는 기회를 가질 수 있다.
다만 아무리 금융 공학의 기초 지식이라 해도 금융 공학에 기본 이론 지식이 없다면 파트5에서 말하고자 하는 내용을 쉽게 이해하긴 어려울 것이다. 저자가 서문에 안내한 바와 같이 어느 정도의 금융 관련 기초 지식이 필요하다.
정리하자면 이 책은 금융 공학에 관련된 지식이 전무한 능숙한 프로그래머에게 가장 적합한 책일것 같다는 생각이 든다. 또는 금융 공학과 관련된 충분한 이론 및 지식을 갖추고 있고 어느정도의 프로그래밍 스킬을 보유하고 있지만 보다 금융 도메인에 특화된 스킬을 쌓고 싶은 이에게도 도움이 될 것 같다.
Python만 다루는 책이나 금융 분석만 다루는 책은 많겠지만 이 두 주제의 교집합을 적절히 심도있게 다루는 책은 드물다는 점이 이 책의 가치를 높이는 요소라 생각한다.
금융이라는 도메인 영역이 한정되어 있어 Python의 방대한 주제를 좁혀주고 더욱 심도있게 집중할 수 있게 해주는 점 또한 장점이다.
더불어 왠만한 입문서 뺨치게 Python의 기초를 핵심만 쏙쏙뽑아 스킬을 잘 전달하고 있으며 금융이라는 주제에 특화된 데이터 과학이 무엇인지 잘 전달하고 있기에 금융, Python, 데이터 과학 중 어느 하나에만 관심있는 독자일지라도 큰 도움을 받을 수 있을만한 양서라 확신한다.
