[리뷰] 자바와 파이썬으로 만드는 빅데이터 시스템
in Review on Review, Book, 빅데이터, 시스템, 하둡, 생태계, Java, Python, 카프카, 스파크, Mongodb, Mysql, 이클립스, 윈도우, 리눅스, Etl

제이펍출판사의"자바와 파이썬으로 만드는 빅데이터 시스템(황세규 저)"를 읽고 작성한 리뷰입니다.
하둡 생태계와 빅데이터 파이프라인을 직접 구축할 수 있게 해주는 가이드. 윈도우, 리눅스 두 운영체제에 Python, Java 두 언어를 연동하며 SQL, NoSQL 두가지 유형의 DB를 연동하며 확실한 이해를 돕는 점이 장점이다.
하둡 Eco 기반의 빅데이터 시스템을 구축하고 이를 데이터 분석 및 AI 모델링에 활용할 수 있도록 데이터 파이프 라인을 구성하는 방법을 알려주는 책이다. 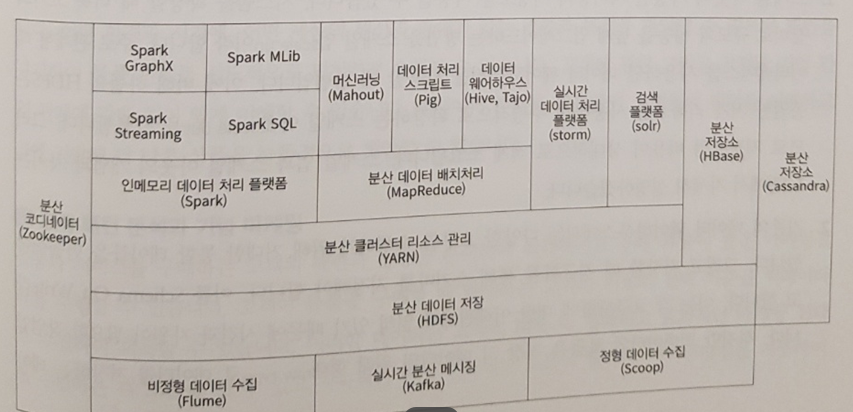
가장 인상깊었던 이 책의 장점은 다양한 언어, DB, OS를 활용하여 빅데이터 시스템을 구축해본다는 점에 있다. 윈도우, 리눅스 두 종류의 OS에 설치해봄으로써 하둡 생태계의 솔루션들이 가지는 특징과 작동 방식을 비교해 볼 수 있고 덕분에 에코 시스템에 대해 깊이있는 이해를 가능하게 해준다.
더불어 현재 레거시 시스템을 활용하기 위해 어떤 OS를 선택하여 구축하는 것이 유리할 지 판단 가능하게 해주며 현재 구축한 OS를 미래에 다른 OS로 대체해야 할지 등의 판단을 미리 시뮬레이션 해준다는 점에서 큰 도움이 되는 책이다.
이런 유형의 주제를 다루는 책은 국내에서 이 책 외에 2권 정도밖에 보지 못했는데 그 중 가장 참고하기 좋은 책이라 생각한다. 또한 그만큼 희소한 내용을 다룬다는 점에 가치가 있다고 볼 수 있다.
몇년 전 이 책 만큼 훌륭한 책을 접했는데 그 책의 경우 다양한 OS나 언어를 연동하지는 않고 있어 하둡 생태계에 대한 깊이있는 이해에 한계를 느꼈고, 더욱이 Cloudera Manager의 패키지의 구성요소를 하나하나 설치하는 과정을 거치고 있어 Cloudera의 라이센스 정책이 변동되거나 버전이 변동되는 경우 호환성 측면에서 애를 먹었던 기억이 난다.
이 책은 대형 빅데이터 시스템 패키지에 의존하는 것이 아닌 하나하나의 솔루션을 직접 설치해보는 과정을 거치기에 제대로 밑바닥부터 빅데이터 시스템을 구성하는 데 큰 도움을 주는 책이다.
또한 앞서 언급한 바와 같이 OS외에도 Java와 Python 언어를 활용하여 데이터 파이프라인을 구축해 볼 수 있다는 장점도 눈에 띈다. 아직 국내 레거시 대부분은 Java 의존성이 높으며 엔터프라이즈 급의 서비스를 가동하는 경우 Java를 쉽사리 포기할 수도 없고 하둡 생태계가 워낙 Java와 궁합이 잘 맞으니 하둡 시스템을 구축하는데 있어 Java를 활용하는 가이드가 소개된 점은 장점이라 할 수 있다.
다만 Java는 Python이 가지는 데이터 생태계에서의 강력함 대비 생산성이 떨어지는 것 또한 사실이다. 이 책은 두가지 언어를 모두 연동하는 예제와 기법을 보여줌으로써 Java언어와의 연동을 통해 내부 매커니즘을 제대로 이해할 수 있게 도와주고 Python으로도 연동해봄으로써 불필요한 코딩을 최소화하여 설계 측면에서의 안목을 신장시켜 준다는 두가지 장점을 모두 갖고 있다.
DB 또한 마찬가지이다. Mysql과 같은 SQL 진영이 가지는 ACID 기반의 트랜잭션 처리 및 배치처리는 물론 MongoDB와 같은 NoSQL 진영의 CAP 이론을 기반으로 한 스케일 아웃 및 실시간 병렬처리의 특성을 모두 익히고 활용할 수 있게 함으로써 적은 시간대비 다양한 레거시의 활용을 가능하게 해준다는 점이 큰 장점 중의 하나라 생각한다.
이를 모두 가능케 하는 개발 환경의 IDE로는 이클립스를 채택하고 있다. IntelliJ나 Pycharm과 같은 Jetbrain 사의 제품이 소개되어도 좋았을 것이나 두가지 IDE를 모두 소개해야 한다는 점 및 온전한 기능을 활용하고 싶다면 유료로 구매해야 하는 만큼 무료로도 훌륭한 개발을 지원하는 이클립스를 선택한 점도 마음에 드는 부분이다. 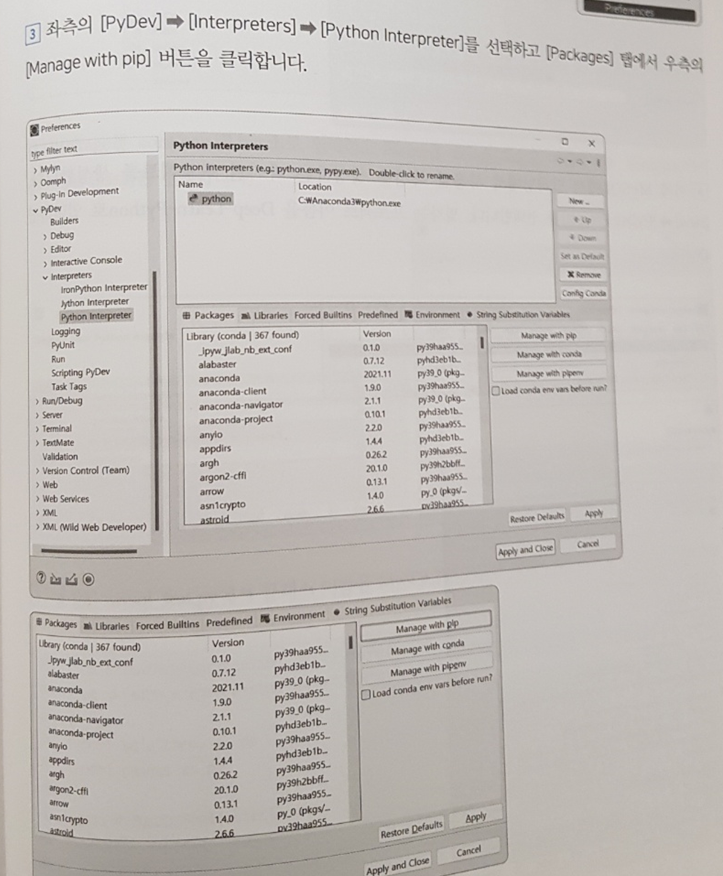
또한 1장에서는 빅데이터를 이해하는 데 필요한 기초 이론을 매우 깔끔하고 이해하기 쉽게 잘 정리하고 있어 놀라웠다. 이 영역의 이론만 다뤄도 능히 책 한 권 이상의 분량이 필요한데 실습을 진행하는 데 반드시 필요한 이론만 깔끔하게 정리하고 있어 매우 인상적이었다. 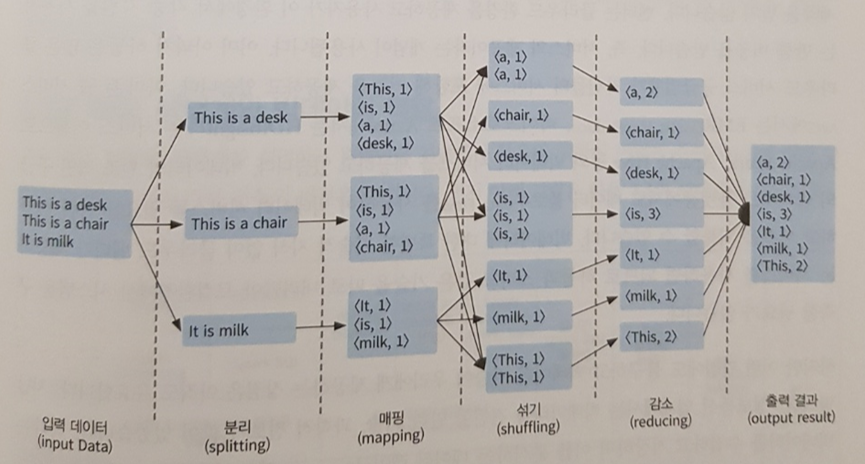
하둡시스템에는 다양한 오픈 소스들의 톱니 바퀴 처럼 물려있지만 이 책은 그 중에서도 하둡, 카프카, 스파크 간의 연동 및 활용에 집중한다. 
물론 조금 더 깊이 들어가면 주키퍼로 병렬 서비스를 통제한다거나, 스쿱과 같은 솔루션을 활용해 데이터를 이기종 시스템에 일괄 전송하는 등의 방법도 소개될 수 있겠지만 이 책에서는 소개되지 않는다.
다만 어떤 시스템에서도 반드시 사용하게 되는 하둡이라는 기본 파일 시스템과 이를 카프카를 이용해서 스파크로 넘겨주고 최종적으로 데이터 마트에 저장하는 일련의 과정을 소개하는데 집중한다.
예제로는 미 연방 재무 지표인 FRED 데이터를 활용한다. 이를 일종의 데이터 레이크로 바라보며 API 키를 발급받아 가져오는 형태의 프로젝트를 진행한다.
FRED의 데이터는 특히 주식 투자를 진행하게 되면 자주 들여다보게 되는 지표가 많다. 예를 들어 장단기 금리차, 통화량 등 유동성 변동, 금리 변동 등의 수치를 얻을 수 있기에 이 책을 통해 기본기를 다진 후 FRED 데이터를 실시간으로 분석해 볼 수 있는 빅데이터 시스템을 만들고 이 수치 간의 모델링을 통해 주가 예측이나 글로벌 매크로 변동을 예측해보는 것도 재미있는 프로젝트가 되리라 생각한다. 아마 저자는 나름의 인사이틀 활용해 지금 내가 말한 것들을 이미 구축하며 수익률을 측정하고 있을거라 생각한다.
이 책의 결과물은 결국 데이터 마트에 저장된 FRED 데이터를 시각화하여 보여주는 것으로 종료된다. 데이터 마트에 저장된 데이터를 Python의 데이터 프레임으로 불러와 간단한 전처리를 거친 후 시각화하여 보여주는 예제인 셈이다. 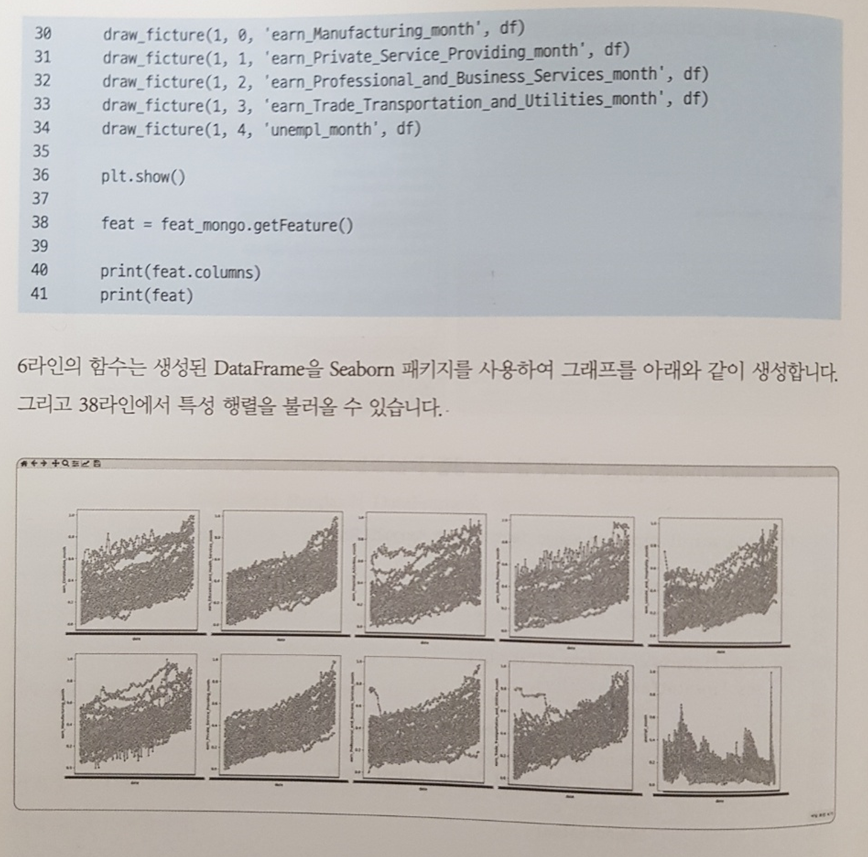
비록 결과물은 단순하지만 중요한 것은 데이터 파이프라인 간 유기적인 구성 및 각 노드를 담당하는 솔루션의 활용법일 것이기에 이 책은 그런 목적을 달성할 수 있도록 충실히 잘 따르고 있다.
그렇기에 데이터 파이프라인을 거쳐 AI 모델링으로 이어지는 부분은 생략되어 있다. 이 부분까지 진행하면 빅데이터 파이프 라인에 집중하는 데 너무 분량이 많아지고 집중력을 떨어뜨릴 수 있기에 적절한 구성이라 생각한다.
그럼에도 한가지 아쉬운 점은 빅데이터 시스템을 구성하는 데 있어 카프카, 하둡, 스파크 각각을 설치하는데 호환성 측면에서 문제가 없는지 사전에 파악하는 방법이나 유의할 점이 소개되었으면 더 좋겠다는 생각이 든다.
책에 소개된 버전 간의 호환성은 문제가 없지만 결국 수년의 세월이 흐르면 독자들은 다시 새로운 버전의 에코 시스템을 구성하게 될 것이고 그 때 호환성에 관한 저자의 시행착오나 노하우가 소개되어있다면 큰 도움을 받을 수 있을거라 생각하기 때문이다.
아무튼 이 책은 빅데이터 시스템을 밑바닥에서 구축해보고 그 안에 숨은 매커니즘을 상세히 이해할 수 있게 도와주는 훌륭한 양서이다. 빅데이터 시스템에 관심이 있거나 파이프 라인을 구축하고 싶지만 지식이 전무한 독자에게 추천하고 싶다. 빠른 시간 내에 빅데이터 시스템의 큰 틀을 이해하는 데 많은 도움을 받을 수 있으리라 생각한다.
