[리뷰] 모두의 한국어 텍스트 분석 with 파이썬
in Review on Review, Book, Nlp, 자연어처리, 한국어, 텍스트, 분석, Python, Chatgpt, 코랩, Tf, Idf, 주제, 분류, 시각화, Lstm, Rnn, 댓글, 분석, 생성

길벗출판사의"모두의 한국어 텍스트 분석 with 파이썬(박조은, 송영숙 저)"를 읽고 작성한 리뷰입니다.
한국어 텍스트 분석 방법을 종합한 책으로 KoNLPy에서 딥러닝까지 적은 분량에 대부분의 실전 기법을 알차게 담아낸 점이 인상적이다.
한국어 텍스트 분석을 처음 접하거나 다른 책이 어려워 새롭게 입문하고 싶다면 이 책으로 시작해 볼 것을 권하고 싶은 도서이다.
대략 300페이지 정도의 많지 않은 분량임에도 한국어 텍스트 분석에 필요한 기본 사항들을 놓치지 않고 잘 전달하고 있는 것 같다. 그동안 유사 도서들을 여러권 봤는데 이 정도 분량에 이만큼의 내용을 전달하는 경우는 흔치 않았던 것으로 보인다.
책은 크게 두 부분으로 구성된다. 1장에서 4장은 데이터 분석 및 파이썬을 다루는데 필요한 기초 지식을 소개한다. 코랩 환경을 구성하여 실습하는 것에서부터 문자열 연산 위주의 Python 기본 문법이 소개되어 있다.
특히 데이터 분석 시 가장 많이 활용되는 세가지 라이브러리 Numpy, Pandas, sklearn이 매우 짧게 소개되고 있는데 생각해보면 여기 소개된 것만 알아도 데이터 분석의 큰 흐름엔 지장이 없는 것 같다.
예전에 당장 사용하지 않을 불필요한 기능을 어렵게 익혀 쉽게 잊혀졌던 허탈감과 비교해보면 일단 이 정도만 챙기고 출발한 후 후반부에 이어질 실습 등을 통해 살을 붙여 나간다면 기억에도 오래남고 더 재미있고 효율적인 학습에 도움이 될 것 같다는 생각이 들었다.
4장부터 본격적으로 텍스트 분석이 시작되는데 후반부에 이어질 가장 기초적인 지식인 BOW나 TF-IDF의 기본 지식 및 실습이 소개된다. 쉽게 말하자면 전자는 단어의 빈도수를 체크하는 개념이고, 후자는 여러 문서에 공통적으로 등장하는 단어보다는 특정 문서에 자주 등장하는 단어의 중요도를 높게 평가하는 개념이라 생각하면 된다.
5~9장은 후반부에 해당한다. 주로 특정 주제를 가진 실습문제를 풀어나가는 과정으로 이어지는데 이 부분들이 이 책의 백미라고 할 수 있다. 뉴스 타이틀을 분류하는 것에서 인프런 댓글 분석에 이르기까지 각각의 데이터 특성과 분석 목적에 따라 새로운 기법들이 등장한다.
뉴스 타이틀 분류 예제의 경우 가장 기본적이고 쉬운 분류 모델을 활용한다. 특히 KoNLPy 라이브러리를 활용한 전처리 방법에서 배울 것이 많다.
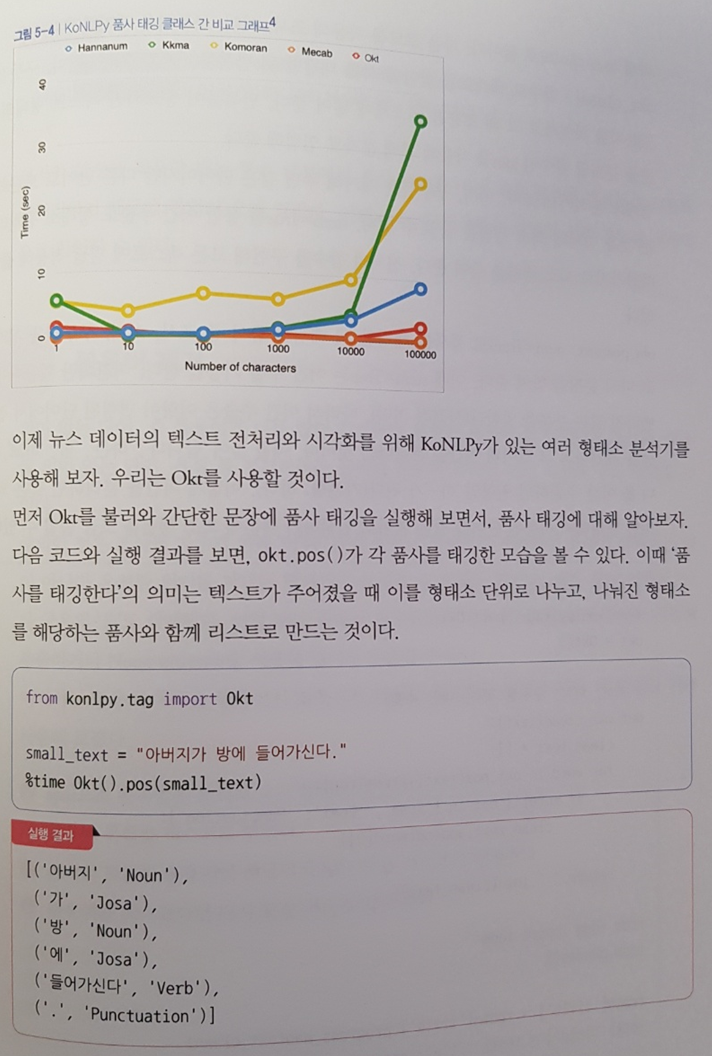
불용어 등을 제거하는 전처리 과정이나 형태소 분석기를 사용한다는 점이 흥미롭다. 다른 언어와 달리 한국어의 특징에 맞게 전처리를 돕는 라이브러리이므로 한국어 분석에 있어서는 반드시 알아둬야 할 지식들이기도 하다.
국민청원 데이터 파트에서는 다양한 시각화 방법을 마음껏 즐길 수 있다. 그동안 꽤 시각화를 해왔다고 생각해왔지만 이 부분에서 몰랐던 새로운 기법을 익힐 수도 있었다. 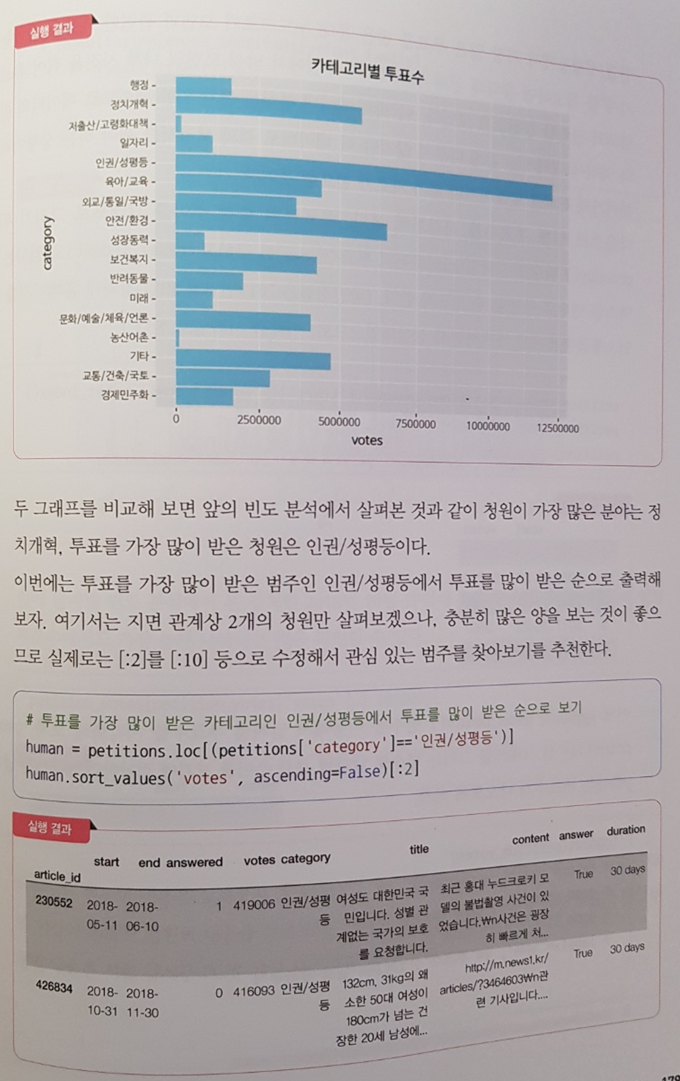
또한 이 장에서는 구글 드라이브를 활용하여 데이터를 입출력한다는 점이 독특한 부분이며 머신러닝 분야에서 비교적 최신 기법이면서 성능이 좋은 LightGBM 모델을 활용하여 앙상블 기법을 맛볼 수 있다.
120다산콜재단 토픽 모델링 예제에서는 본격적으로 확룰이나 딥러닝과 관련된 전문적인 기법들이 활용된다. 잠재 디리클레 할당이나 RNN, LSTM 모델도 등장한다. 딥러닝 실습을 통해 NLP 분야에서 딥러닝의 위력이 얼마나 뛰어난지 체감할 수 있는 예제이기도 하다. 
물론 딥러닝의 모델 하나하나도 처음 접하면 배우고 알아둬야 할 것이 너무 많기에 이 책의 예제만으로는 부족한 것이 사실이지만 일단 딥러닝으로 무엇을 해낼 수 있는지와 더불어 프로그래밍의 디자인 패턴 처럼 대략 이런 패턴으로 딥러닝을 설계, 개발한다는 정도의 블루 프린트를 익힌다고 생각하면 좋을 듯 하다. 차후 본격적으로 딥러닝 개발에 좋은 설계도 역할을 할 수 있는 예제라 생각했다. 또한 pyLDAvis 라이브러리를 이용한 시각화가 소개되어 있어 이 책은 확실히 시각화 파트로 배울 점이 많은 책이라는 생각이 들었다.
인프런 이벤트 댓글 분석 예제에서는 군집화와 같은 비지도 학습이 소개된다. 더불어 그동안 배운 것들을 실제 업무에 적용해 볼만한 주제를 찾는다거나 당장 도움이 될만한 분석 기법을 만드는데 도움이 되는 장이라 생각했다.
마지막으로는 ChatGPT나 뤼튼을 활용하는 방법도 간략히 소개되어있다. 뤼튼은 잘 알지 못했는데 한국어 생성 LLM 서비스인듯 하다. 덕분에 한번 이용해봐야겠다.
이 책은 특히 저자 분의 실력이 검증된 분이기에 더욱 추천하고 싶은 책이기도 하다. 예전에 박조은 님의 인프런 강의를 들은 적이 있었는데 시원시원하게 유창한 설명과 더불어 전광석화와 같은 속도로 코딩 타이핑을 따라가며 저자분의 생각을 읽어나간적이 있다.
강의 전달력이 너무 좋으시고 데이터 분석 분야로 아는 것이 많으신데다 그간 고민한 것을 전달하는 능력이 일품인 전문가라는 생각이 들었는데 그 실력과 경험이 이 책에 녹아있어서인지 책의 내용과 전달력 또한 역시 기대한 바와 같았다.
한국어를 처음으로 분석하는 분은 이 책을 일독할 것을 권하고 싶다.
