[리뷰] LLM 서비스 설계와 최적화
in Review on Review, Book, Llm, 비용, 최적화, 추론, 모델선택, 인프라, 배포, 트렌드, 파인튜닝, 프롬프트, 모니터링

한빛미디어출판사의"LLM 서비스 설계와 최적화(슈레야스 수브라마니암 저/김현준, 박은주 역)"를 읽고 작성한 리뷰입니다.
LLM 기반 서비스를 구축하는 데 있어 반드시 알아야 할 설계 지식과 성능-비용 간 트레이드 오프 전략을 다룬 필독서.
오랫동안 기다려온 책이 출간되어 너무 기뻤다. 이 책은 LLM 서비스 구축을 위한 거의 모든 것을 다루고 있고 특히 그동안 레퍼런스가 부족했던 내용들이 가득담겨 있어 매우 유용하다.
LLM 서비스 구축을 위한 핵심 주제인 설계, 인프라 구성, 파인튜닝, 성능-비용 간 트레이드 오프 문제를 다루고 있으며 특히 전략을 세우는 데 있어 데이터 기반의 가이드를 제시하고 있고 AWS 인프라를 담당하는 경력을 갖춘 저자의 글이기에 더욱 신뢰가 간다.
그동안 LLM을 만드는 데 집중해 온 시기였다면 이제 본격적으로 이를 활용하여 저마다의 가치에 AI를 입히고 서비스를 고려하는 단계에 이른 것 같다.
이를 위해 고민해야 할 사항이 많지만 그 중에서도 가장 두려운 요소는 역시 비용 문제이다. 예시로 GPT-4의 경우 모델 훈련 비용이 9천만 달러(약1700억원)에 육박 했다고 하니 일반 기업으로는 LLM 구축은 요원한 일이다.
그렇다고 잘 만들어진 LLM 활용에 집중한다면 비용 문제에서 해방될 수 있을까? 아래 그림은 LLM 활용 또한 비용 문제가 심각하다는 것을 실감나게 보여주는 좋은 예시이다. 
이래 그림은 LLMOps를 한눈에 볼 수 있게 도와준다. 시퀀스다이어그램은 물론 서비스 각 단계가 상당히 복잡하다. 각 단계별로 고려해야 할 요소들이 많으니 비용이 많이 들 수 밖에 없다. 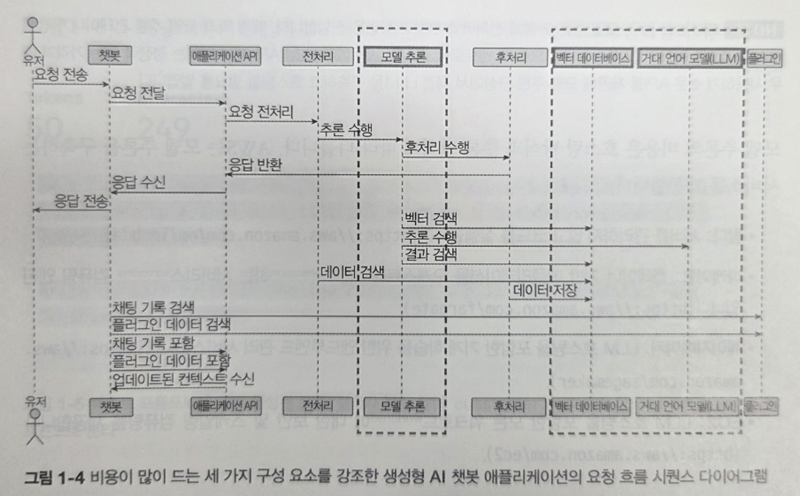
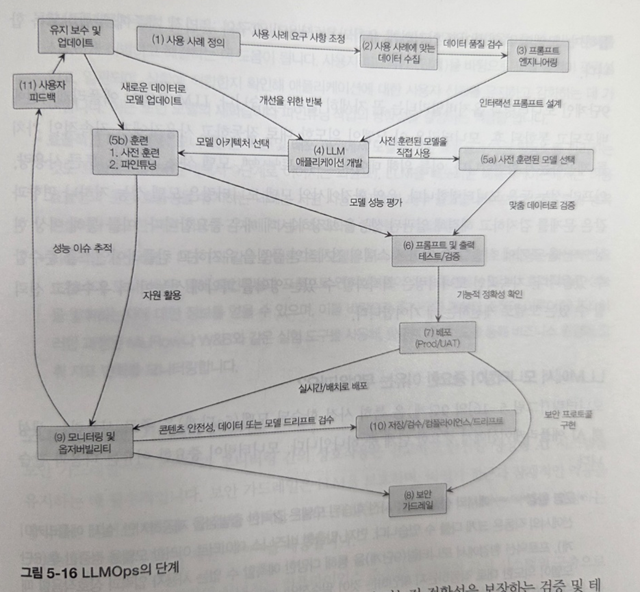
이에 성능과 비용의 트레이드 오프의 적정선을 찾는 것이 중요한 문제인데 아래 도표를 통해 깔끔하게 파악할 수 있다. 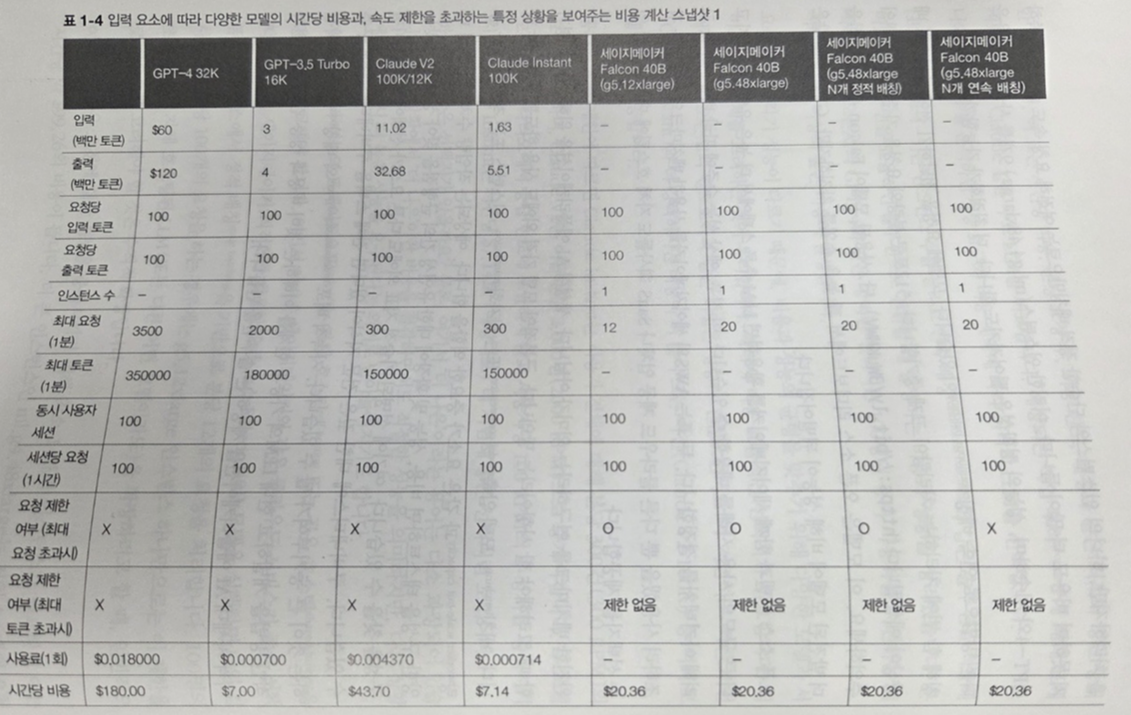
벡터DB의 벤치마크 자료도 어느 기종의 벡터DB를 선택해야 할지 판단하는데 많은 도움을 주는데 이렇듯 저자는 흔히 보기 어려운 깊은 인사이트가 담긴 자료를 다양하게 제시하고 있어 실무에 많은 도움이 된다.
이렇게 1장에서 LLM 관련 전반적인 비용 문제의 개요를 다뤘다면 2장에서는 파인튜닝에 집중하여 비용 문제를 해결하는 방법을 다룬다.
비용을 1순위로 두면서도 사내 LLM 기반 인프라 설계 전략을 수립하는데 다양한 방향성을 제시하고, 더불어 최대한 원하는 성능을 보장할 있는 다양한 방법론을 제시하고 있다.
먼저 비용을 산정하는데 있어 매우 유용한 스케일링 법칙이 등장한다. LLM 운영에 있어 가장 많은 제약을 받는 자원은 GPU 메모리이다. 아래 그림은 N(모델 파라미터 수)가 40 x 10^9 인 경우 추정되는 예산(C)을 보여준다. 덕분에 실제 운영 비용을 미리 예측하는 데 있어 꽤 유용한 팁을 얻을 수 있었다. 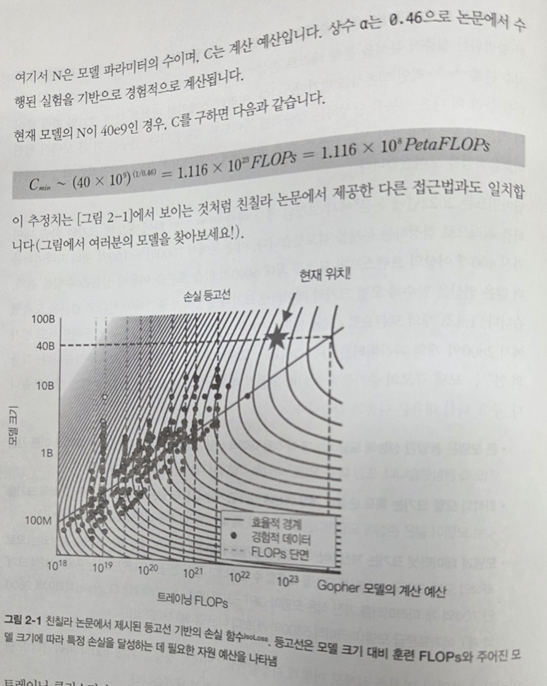

이를 통해 파라미터를 얼마나 효율적으로 관리하는 것이 중요한 문제인지 도출된다. 책에서는 파라미터 효율적 파인튜닝(PEFT)으로 일반적으로 흔히 사용하는 프롬프트 튜닝은 물론, 실제 영향을 미치는 가중치는 적을 것이라는 것에 착안한 LoRA 기법을 비롯 프리픽스 튜닝, P튜닝, IA3와 같은 다양한 연구 결과 및 가이드를 제시한다.
그 외에도 특정 작업이나 도메인에 맞춤화 하는 전략, 저차원 행렬 분해 등 다양한 방법이 소개되는 데 개인적으로 미처 존재 여부 조차 알지 못했던 다양한 아이디어를 얻을 수 있어 매우 만족스러웠다.
3장에서는 추론 테크닉에 집중한다. 통상적으로 널리 알려진 대표적인 프롬프트 엔지니어링 기법 - 지시 내리기, 형식 지정, 예시, 평가, 단계별 추론 - 을 잘 정리한 후, 이를 통해 비용을 절감할 수 있는 다양한 방법을 소개한다.
예를 들어, tiktoken 라이브러리를 사용하면 토큰수를 미리 파악하는데 용이하다. 그 외에도 답변 길이를 100자 이내로 제한한다든가, 사용자의 요청을 분해하는 방법도 있다. 프롬프트를 배치 방식으로 관리하거나 텍스트 요약을 활용하여 프롬프트를 제어한다면 토큰 호출 비용을 크게 절감할 수 있다.
그 외에도 자주 발생하는 질의에 대한 백터 스토어 캐싱 방법, 긴 문서를 위한 체이닝 기법도 소개하고 있다. 긴 문서를 잘개 쪼개 병렬 처리 작업으로 비용을 절감시키는 방안인데 아래 그림은 한 눈에 개념을 이해할 수 있도록 도와준다. 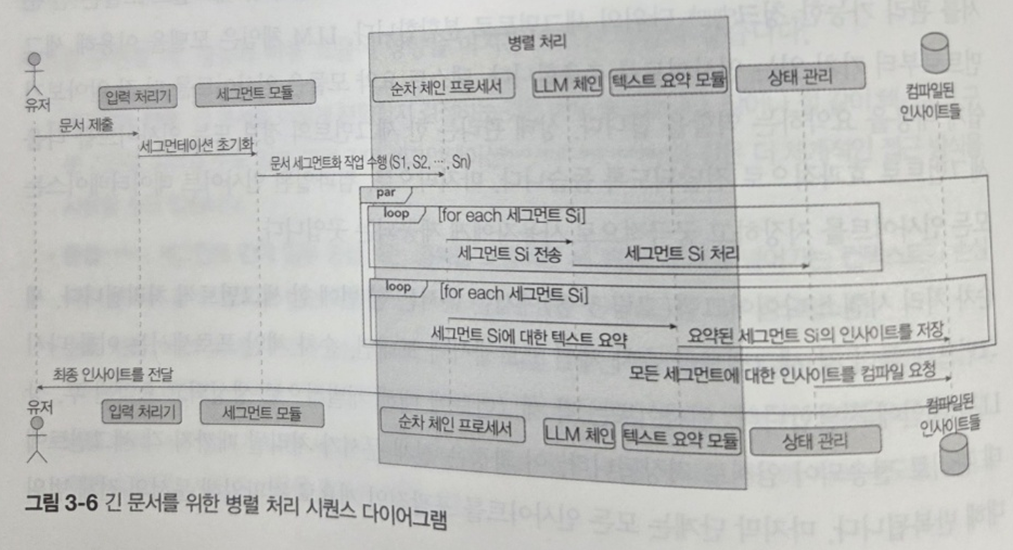
이 외에도 양자화 기법 등을 활용한 모델 최적화 방법이 소개되는 데 이는 이어지는 4장에서 보다 자세히 다룬다.
4장은 트레이드 오프를 고려한 소형 모델을 대안으로 제시한다. 이를 위해서는 조직별 서비스 목적을 분명히 파악하여 비용 문제와의 타협점을 찾는 것이 중요하다.
실제 업계에서 소형 모델을 도입하여 비용을 절감하면서도 원하는 성능을 발휘하는 성공사례를 몇가지 소개한다.
양자화를 활용한 Mistral이 대표적인 예인데 이는 이미 2장에서 소개된 바와 같이 양자화 버전에 따른 비교 예시를 통해 직관적으로 장점을 이해할 수 있다. 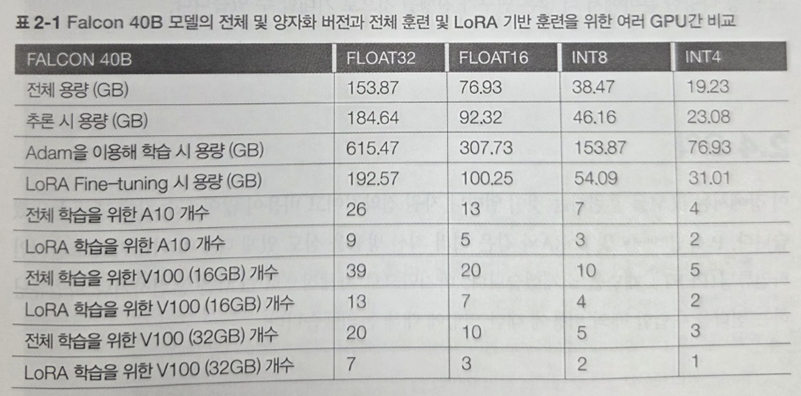
Zephyr에서 활용한 지식증류 아이디어도 주목할 만하다. 소형 모델임에도 불구하고 다른 대형 모델 대비 성능이 크게 뒤떨어지지 않는다는 점에서 또 다른 대안이 될 수 있다. 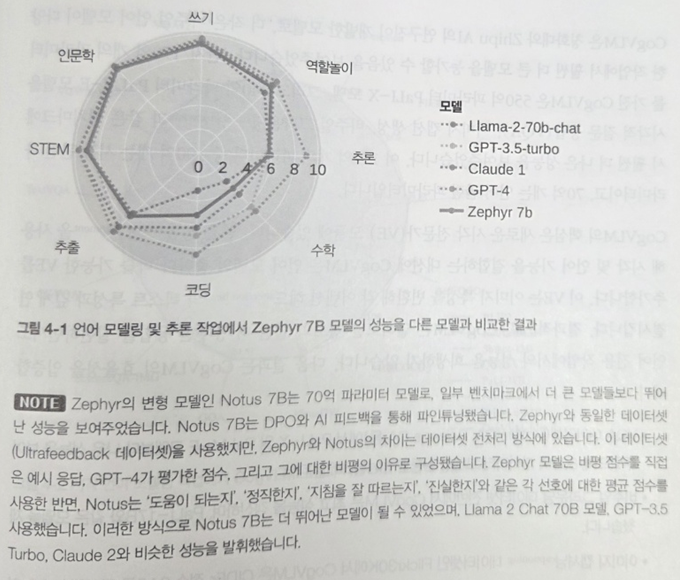
5장에서는 IT나 배포 등 기반 인프라에 대한 비용 절감 방안을 고민한다. 아래 도표와 같이 모델별 로드 시 메모리 요구양을 보면 효율적 인프라 설계의 중요성이 실감난다. 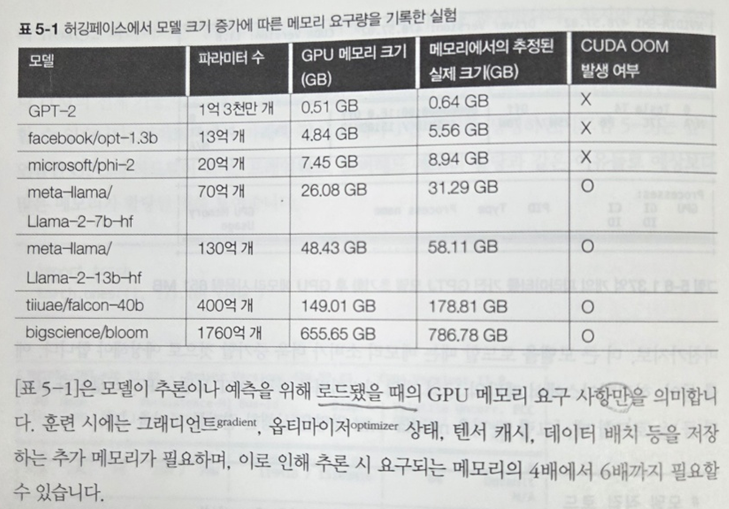
이 문제를 해결하기 위해 어떻게 메모리를 효율적으로 사용할지에 대한 다양한 연구 결과 및 방법론이 소개되는데 모델의 일부 파라미터만 저장 및 처리하는 방식이 그 중 하나이다.
그 외에도 16비트와 32비트 부동소수점을 혼합적으로 활용하는 혼합정밀도 표현 방식, 허깅페이스의 accelerate 라이브러리와 같이 CPU-GPU간 전환 활용을 고려한 후처리 양자화, 통상 GPU 메모리의 30% 이상을 차지한다고 알려진 KV 캐시를 효율적으로 관리하는 방법이 소개된다.
특히, KV캐싱 문제에 있어 PagedAttention 기법이 주목할 만하다. 마치 운영 체제 분야의 가상 메모리 관리 방식과 유사하여 IT 전공자들이 이해하는데 큰 어려움이 없다. 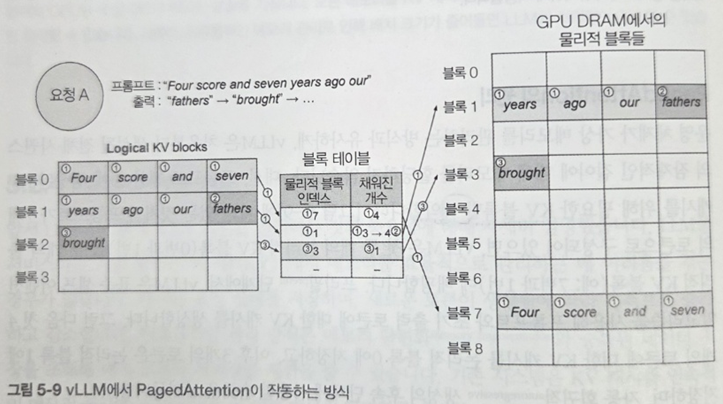
최적화된 병렬 자동화 기법을 이용한 AlphaServe 방식도 눈에 띈다. 그 외에도 추측을 활용한 시퀀스 스케줄링인 S3기법이나, StreamingLLM 등이 소개된다. 개인적인 견해로 StreamingLLM은 이미 활용해 본 적이 있는데 비용 절감 측면에서 매우 우수했다. 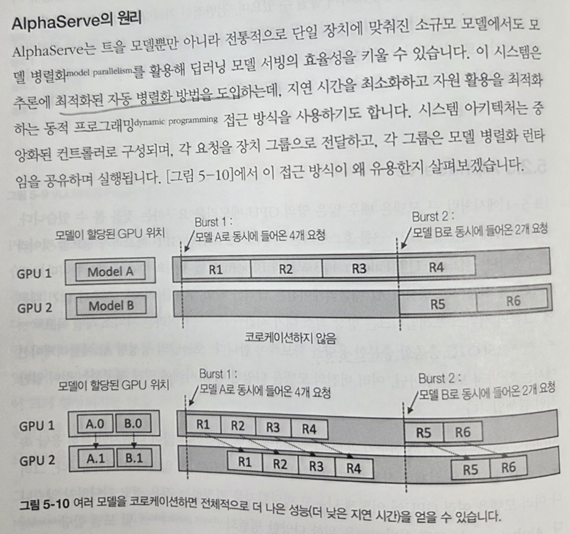
추론 가속화도 솔루션이 될 수 있겠는데 GPU 가속 도구를 활용하는 방법이다. 그 외에도 LLMOps의 복잡한 각 단계를 얼마나 잘 모니터링하며 비용을 절감할 수 있는 아이디어를 착안하는 것 또한 중요한 해법의 열쇠가 될 것 같다.
마지막 6장에서는 앞서 배운 것들 외에도 소프트 스킬 측면에서 성공하기 위한 전략을 제시하고 있어 유익하다. 구체적으로 인력 관리 측면이나 미래를 위한 트렌드를 가이드 해준다.
먼저 인력 측면에서 다양한 전문가가 필요한 데 도메인, 데이터 전문가는 물론 숙련된 레이블러, 법률 전문가도 필요하다. 더불어 교육 - 혁신 환경 조성 - 내부 프로세스 검토의 선순환을 위한 HR이 중요한 부분이다.
특히, 10인 정도의 최초 팀구성에 대한 예시가 팀 빌딩에 있어 많은 도움이 된다. 
마지막으로 미래 트렌드를 세가지로 종합하여 보여주는데 가장 최신 트렌드는 Agent 방식인 것 같다. 특히, 최근 MCP나 A2A의 등장으로 인해 피할 수 없는 대세 표준 혹은 프로토콜로 자리매김할 것 같다.
Agent를 실제 구현 및 테스트 할 수 있는 베이스라인 코드 소개를 끝으로 이 책의 긴 여정은 마무리 된다.
정리하자면 회사에 LLM 서비스를 도입하는 데 있어 반드시 검토해봐야 할 주제들을 거의 모두 다루고 있는 현 시점 매우 귀한 가이드라고 할 수 있겠다.
이 책이 제시하는 하나하나의 방법론들을 숙지 및 고민하지 않고 서비스화에만 몰입할 경우 추후 감당할 수 없는 비용 문제에 같은 고생을 반복하게 될지 모른다. 그렇기에 LLM 서비스를 고민하는 관련자라면 반드시 정독할 것을 추천하는 바이다.
