[Goal] 한걸음 한걸음, 데이터 과학자(Data Scientist)가 되는 방법
in Dev on Competition, How, To, Become, Data, Scientist, 데이터, 사이언티스트, 과학자
개요
Data Scientist가 되기 위한 방법들을 정리한 글입니다.
- 목차
데이터 사이언스, 데이터 사이언티스트란?
- 데이터 사이언스란?
데이터 과학(data science)이란, 데이터 마이닝(Data Mining)과 유사하게 정형, 비정형 형태를 포함한 다양한 데이터로부터 지식과 인사이트를 추출하는데 과학적 방법론, 프로세스, 알고리즘, 시스템을 동원하는 융합분야다. (위키백과)
데이터 사이언스, 사이언티스트는 사람마다 정의가 달라 용어 자체에 집착하는 것은 시간 낭비일 뿐이다.
대신 우리가 진짜 원하는 것들 - 데이터 사이언티스트가 일하는 기업, 직군, 직무, 제품, 갖춰야 할 스킬셋 - 을 알아보는 것이 훨씬 효율적이다. 최근 유명한 인포 그래픽들로 대체한다.
- AI 관련 기업, 제품, 업무도메인 등

- 데이터 사이언티스트가 갖춰야 할 역량

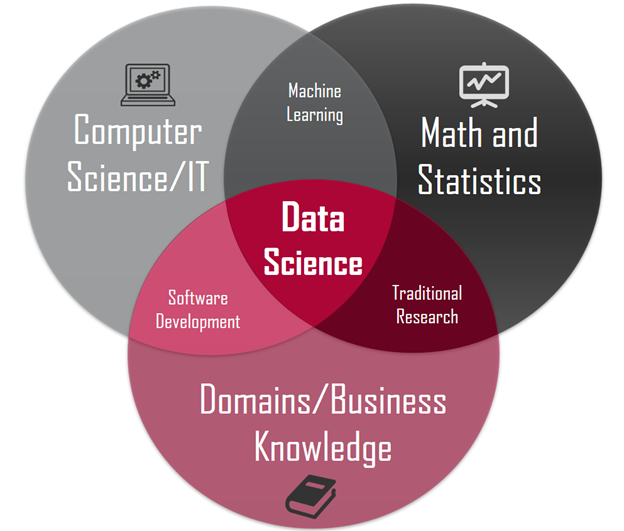
- 데이터 직군 큰그림
그야말로 망망대해다. 이런 규모의 다양성과 융합 때문에 용어의 정의가 어렵다. 따라서 본 포스팅에서는 데이터 사이언티스트의 정의를 최대한 광의적으로 해석하여 데이터, AI, 빅데이터 전반에 걸쳐 필요한 인재라고 정의한 후 포스팅을 작성하였다.
이제 데이터 사이언티스트가 되기 위한 전략 및 준비과정에 대해 알아보자.
빠르게 데이터 사이언티스트가 되기 위한 방향잡기
AI 및 데이터 사이언스에 관심있는 분들의 수다(?) 한 번 들어보자.
“딥러닝을 배워야 한다, Python vs Jilia vs R?, TensorFlow를 알아야 한다더라, 최근에 2.0 등장!, PyTorch/Keras/Torch/Caffe/CNTK/Theano..?, 코딩이 중요한 것이 아니란다, 수리통계학이 중요하다, 미적분/확통/선대와 씨름 좀 해볼까?, 기껏 LSTM에 적응했는데 다 필요없고 BERT!, GAN/DQN/ANN/DNN/RNN/CNN/LSTM/ResNet/RBM/DBN/AE/GRU/styleGAN..?, 전이학습과 Auto-ML이 대세다, IBM Q Experience과 텐서플로 퀀텀(TFQ)도 등장했는데 양자 컴퓨팅 준비해야지, Serving은?, DARPA XAI는?, 실무의 꽃은 전처리지! No+SQL/OpenCV, 파이프라인 ELK/Hadoop-Spark, 지도 / 비지도 / 강화학습, PC나 서버 장비 스펙은?, Colab을 어떻게 사용하지?, 비즈니스 관점의 문제 및 인사이트 분석/도출도 쉽지 않고, 스토리텔링 및 사내 의사소통은 어찌하며, 시각화는 또 어쩐다,…등”
한도 끝도 없어서 여기까지만 표현하겠다. 이 역시 망망대해다. 지금까지 위에 요약한 사례들은 데이터 사이언티스트에게 가장 중요시되는 역량이 빠른 학습 속도 및 적용 능력이라고 말하는 이유를 대변해준다.
이런 폭풍속에서 헤쳐나가는 방법은 먼저 가고자 하는 방향을 구체적으로 정하는 일일 것이다.
- 지금까지 쌓아온 스킬, 재미있는 분야, 적성 고민하기
- 시장이 원하는 사람되기 : 당장 개인 혹은 기업원하는 스킬셋, 세상이 원하는 제품
- 세부 연구분야 정하기
- 직군 정하기
- 업무도메인
현 직장에서 데이터 사이언티스트가 되어보기
데이터 사이언티스트가 되기 위한 방법은 다양하다. 이직, 대학원 진학, 개인 프로젝트 진행, 창업, 꾸준한 학습 등 여러 방법이 있겠지만 모두 상당한 리스크가 존재하기에 심사숙고해야 한다. 반면 현재 소속된 회사에서 새로운 직무, 직군에 편성되는 것은 비교적 안전하고 쉬운 방법일 것이다.
- 예) LG전자 - 사내 해외 대학 위탁교육 프로그램, LG전자-KAIST 인공지능 고급과정 등
이직
현 직장에서 데이터 사이언티스트가 될 방법을 찾지 못했다면 가장 일반적인 전환 수단은 역시 이직일 것이다. 현 직장이 적성에 맞지 않는데 평생 그 테두리에 갖혀 스트레스 속에 시간을 낭비한다는 것은 굳이 말하지 않아도 지옥과 다를바 없다.
- AI 및 빅데이터 분야 채용정보 모음
- 한번에 이직이 어려운 경우 우회방법
- 포스코 청년 AI 빅데이터 아카데미 : 우수 수료자 입사 우선권 제공
- 스타트업 : 열정은 가득하나 쌓아온 커리어, 스킬이 변변치 않을 때 고려 가능. 기회의 장이자 연봉 및 안정성 등의 문제점도 있음
창업
데이터사이언스로 성공적으로 이직을 했다고 할 지라도 자신이 정말 원했던 분야의 연구 혹은 실무를 담당할 가능성은 낮으며 직장인은 언제나 회사의 부품임을 감안하여야 한다. 정말 본인이 하고 싶었던 일만 하고 싶다면 결국 언젠가는 창업의 문을 두드릴 수 밖에 없으므로 항상 관심있게 지켜봐야 할 핵심 선택지이다.
- 정부 지원정책 활용
- 초기 창업 지원신청 : 5천만원 ~ 1억 (앱개발 등 주력 사업이 아닌 협업을 통한 서비스 구축에 활용하면 좋다.)
- R&D 사업 선정 지원금
- 사무실 지원, 딥러닝 서버 지원 등
- 국비지원 교육 : 단, 별로 추천하고 싶진 않다. 하지만 본인의 실력에 따라 고려대상이기도 하고 소정의 용돈도 받을 수 있다.
- 엔젤투자, 엑셀러레이터 투자 유치
- 직업 특수성에 의한 장점
- 인테리어, 장비, 재료, 임대료, 권리금, 보증금 불필요
- 융합 학문 특성 상 다양한 분야와 연결 가능 : 채용, 요식업, 법률,
- 노하우 축적 및 모델 재활용
- 시장 수요 급증 및 정부 정책 지원 활용 가능
- 신생 분야인만큼 전문가의 절대적인 수가 부족하고 소위 객관적인 스펙(?)이 전무하므로 자기PR이 중요하다.
- 선점 효과를 통해 얻은 고객평, 리뷰, 입소문 등이 지속가능한 시간적, 경제적 자유를 제공해줄 수 있다.
지금이라도 대학원을 가야할까?
논란이 많은 부분이나 유경험자들의 의견을 토대로 가장 중요한 장단점 몇가지를 꼽아보았다. 개인적으로는 대학원에서 얻을 수 있는 능력들을 이미 갖추고 있는 분이라면 가지 않아도 큰 문제될 것은 없으나 그렇지 않다면 심각하게 진학을 고민해봐야한다고 생각한다.
- 가야하는 이유
논문과커뮤니케이션스킬- 논문을 빠르게
읽고, 구현하고, 쓰는능력이 매우 중요하다. 좋은 논문과 아이디어 하나에 예측의 정확도가 급변하는 상황 속에서 논문때문에 팀원들과 커뮤니케이션이 안된다면? 내가 구성원이어도 절대 안뽑겠다. - 논문은 그야말로 AI의 언어이다.
- 논문을 빠르게
- 대학원 생활 수년간 AI 분야에 필요한 기본 역량과 자세를 디폴트로 얻어온다. 세상에 쌓여 온 데이터, 지식을 바탕으로 실험을 통해 유의미한 인사이트를 얻는 논문을 쓰는 과정에서 p-value이니, 가설수립에서 과학적 실험/설계 등으로 수년간 고민을 했다는 것은 학부생 출신이 쉽게 범접할 수 없는 경험이다.
- 가지 말아야 하는 이유
- 이미 논문을 이해하고 빠르게 구현체를 만들 수 있는 사람에게는
돈, 시간 낭비이다. 연구 분야가 협소하여 차후 기업에서 담당할 직무간 불일치 가능성이 크다.- 해외라면 모를까? 정부지원을 받는 국내 유수 AI대학원들도 교수 초빙단계부터 몸살이다. 교육 커리큘럼의 신뢰도도 의심스럽다. Matlab, SAS, IBM 모델러, RapidMiner, 나임같은 구시대의 도구를 사용하기도 한다. 미국의 경우 2개 정도의 AI대학원에 약 1조원 정도의 예산을 집중하고 있고, 중국의 경우 대학 학과만 연간 400개 이상 신설하는 상황에서 우리 나라의 경우 두 나라에 비해 학과 신설은 커녕 택도없는 예산으로 AI 대학원만 7개를 지원하는 등 정책적 문제점을 지적받고 있다.
- 이미 논문을 이해하고 빠르게 구현체를 만들 수 있는 사람에게는
- 주의해야 할 점
- 본인이 하고 싶은 연구분야와 지도교수님의 연구분야가 정확히 일치해야한다.
- 영수증 처리, 제안서 작성, 수업자료 준비, 조교실습, 청소, 세미나참여, 대리기사, 짐꾼 등 허드렛일로 인한 시간 및 노동력 낭비는 감수해야한다.
- 대학원생 때 알았더라면 좋았을 것들
롤모델 설정 및 끊임없는 학습
지금까지 직접적인 진로의 변경에 대해서 알아보았다면, 앞으로는 원활한 커리어 전환을 위한 학습 및 스킬셋을 획득하는 방법을 중점적으로 기술하고자 한다.
- 링크드인(LinkedIn)에서 유명 데이터 사이언티스트 분들을 수시로 검색한 후 커리어에서 힌트를 얻는 방법이 가장 실용적이다.
더불어 평소 우리가 떠올리는 과학자의 이미지가 그러하듯 데이터 사이언티스트도 끊임없는 연구 및 학습은 필수 조건이다. 서두에서 언급했던 방향잡기에 대한 답 또한 끊임없는 학습과 노력 끝에 찾을 수 있다. 구체적인 커리어 및 학습을 위한 방법들을 살펴보자.
프로젝트 및 블로그
- 캐글 등 Competition 참여
- 캐글의 중요성은 아무리 언급해도 지나치지 않다. 특히 현재 데이터 사이언스와 무관한 직무를 수행중인 분들은 이 곳에서 마스터 혹은 메달을 획득하는 것 만큼 객관적으로 신빙성있는 실력을 어필할만한 수단이 거의 없다. 그 외에도 앞서 방향잡기에서 말씀드린바와 같이 다양한 업무 도메인을 미리 경험함으로써 본인이 가고자 하는 범위를 보다 세부적으로 축소시킬 수 있고 그만큼 학습과 커리어에 집중하기 쉬워진다. Notebooks 게시판에 다른 참여자들의 해결 기법 및 인사이트를 얻을 수 있고, Discussion에서 질의응답 내용을 읽어보며 내용을 파악할 수 있다.
- 참고-데이터 과학 경진대회 사이트 모음
- 외주 및 프리랜서 플랫폼
- 인력 수요에 비해 프리랜서가 전무하여 Small 커리어 쌓기에 안성맞춤
- 주요 의뢰업무 : 로그/센서/게임/SNS 분석, 시장조사 의뢰, 추천서비스, 정부과제 용역 및 컨설팅, 공공 자문 보고서 작성, 논문 데이터 분석 의뢰 등
- 그 외 재능거래 사이트의 비교 분석글
- 크몽 - 데이터분석/인공지능/머신러닝
- 재능넷
- 오투잡
- 위시캣
- 프리모아
- 블로그
- 학습 내용을 효율적으로 정리할 수 있고 열정과 전문성을 어필할 수 있는 좋은 수단이다.
- 본 블로그에도 구축을 위한 좋은 방법을 다루고 있으므로 관련 글을 추천한다.
논문, 특허, 저서, 강연
- 논문
- 논문의 중요성은 위 대학원 진로 파트에서 이미 언급했으므로 생략하고 셀러던트로서 혹은 학사 출신으로서 논문을 쓰기 위한 방법에 대해 간략히 언급하고자 한다.
- 논문을 실제코드로 구현하고, 개량해보고 공헌도를 높일 수 있는 논문 게재로의 선순환 능력을 갖춰야한다.
- [논문 초보자를 위한 Tip]
- 세부 연구분야 선정 > 타깃저널 선택(격월/계간) > 벤치마킹 논문 > 리뷰 논문 등 메타분석 > 연구주제 선정(최근 화두)
- 처음에는 논리전개 방식을 배우고, 연구 대상과 방법만 바꾸는 방식을 추천
- 변형, 새로운, 혼합에 초점을 맞추되, 구글 스칼라 검색 시 30개 이내 검색되면 딱 좋은 분야
- 새로운 업무 도메인의 데이터로 분석한 연구도 새로운 공헌으로 인정받을 수 있다.
- 선행연구 파악 : 리뷰(메타분석/literature review) 논문으로 최신 연구분야에 대한 체계적 정리
- 저자, 제목, 연도, 인용수, 연구목적, 연구방법, 비고 등으로 테이블 정리
- 구글 스칼라, 대학 도서관 포털, SCI-HUB 사이트에서 검색, 결론 및 시사점에 현 시점 부족한 연구도 정리가 되어있음
- 국내저널 : 지능정보연구, 한국경영과학회지, Information Systems Review
- 해외저널 : IEEE Access, IEEE Transactions on Big Data, Information Systems Research
- 논문 구현 사이트
- KCI 등재지
- 참고-논문 읽는법, 쓰는법, 투고하는법
- 특허
- 특허의 유명무실에 대한 논쟁은 논외로 한다. 다만 가급적 본인이 회사 업무 과정에서 등록하면 수월할 것이다.
- 추천도서-실전으로 배우는 발명·특허
- 추천도서-나는 특허로 평생 월급 받는다
- 저서
- 평소 열심히 공부해 온 것들을 가독성과 전달력을 살려 책을 출간하는 방법도 전문성을 인정받기 위한 좋은 수단이다.
- 강연
- 데이터 사이언티스트가 되기 전 이 기회를 만나기는 쉽지 않겠지만 이 만큼 인맥을 빨리 형성하고 입사 추천을 받기 좋은 수단도 없다.
자격증
없는 것보다는 낫겠지만 굳이 추천하고 싶진 않다. 적어도 필자에겐 영화배우 하정우님보다 셀럽이신 네이버AI 임원 하정우님께서 자격증의 가치가 정말 무의미 함을 페북에 종종 올리시는데 분명 이유가 있다 생각한다. 하지만 커리어를 위해서가 아니라 학습 자체를 위하여 또, 동기부여를 위한 것이라면 굳이 취득하지 않을 이유 또한 없기에 정리해본다.
- Google Certificate for ML
- 구글이 인정하는 자격증으로 최근 등장하여 텐서플로 코리아 페북 커뮤니티에서 약간 웅성웅성함. 하지만 취득자들 말로는 실무 경력에 비할만큼 가치있는 자격증은 아니라고 함.
- 핸드북 가이드 정리글
- 추천강의
- Google Cloud Certified Professional Data Engineer
- 빅데이터 분석 기사 (2020 예정)
- 한국산업인력공단 - 사회조사 분석사
- 통계학과 전공자들에게는 나름 유명한 시험. 확통 부분을 제외한 설문조사 등 사회학과 관련된 부분은 데이터 사이언스와는 큰 관련이 없다.
- 데이터산업진흥원 - ADP
- 그나마 대안이 없어 약간의 의미는 인정받는 시험. 동 기관에서 빅데이터 분석 기사 시험도 주관할 예정.
- 필기 시험은 쓸데없는 주입식, 암기식 위주로 가치가 없다 생각하며, 실기 시험은 최근들어 수준이 많이 향상되었으나 행정처리 미숙으로 응시자들의 불만이 상당함.
- 한국경제 - 경영 빅데이터 분석사
- 비지니스 측면에서 문제의 정의 및 기획을 위한 안목 향상에는 도움이 되나 기술적으로는 가치가 거의 없음.
추천할만한 교재 및 커뮤니티
언제나 전문가가 되기 위한 첫발은 책에 있고, 그 완성은 사람에 있다. 양서를 다독하고 커뮤니티 등 사람 모임에서 좋은 인간관계를 쌓는 것의 중요성은 두말할 나위 없다.
- 원서 : 너무 많아 국내외 유명 데이터 사이언티스트 분들이 이구동성으로 추천한 서적들만 모았다.
- Machine Learning : A Probabilistic Perspective (by Kevin P. Murphy)
- Artificial Intelligence: A Modern Approach (by Stuart Russell and Peter Norvig)
- Deep Learning (by Ian Goodfellow)
- Neural Networks and Deep Learning (by Charu Aggarwal)
- Reinforcement Learning (An Introduction by Richard S. Sutton)
- Causal Inference in Statistics (A Primer by Judea Pearl)
- Fluent Python: Clear, Concise and Effective Programming (by Luciano Ramalho)
- Linear Algebra Done Right (by Sheldon Axler)
- Probability Theory: A Comprehensive Course (by Achim Klenke)
- The Elements of Statistical Learning (by Trevor Hastie)
- Machine Learning : A Bayesian and Optimization Perspective (by Sergios Theodoridis)
- Probabilistic Graphical Models, Principle and Techniques (by Daphne Koller, Nir Friedman)
- Information Theory, Inference, and Learning Algorithm (by David J. C. MacKay, David J. C. Mac Kay)
- Pattern Classification (by Richard O. Duda, Peter E. Hart, David G. Stork)
- Pattern Recognition and Machine Learning (by Christopher M. Bishop)
- Recommender Systems (by Aggarwal, Charu C.)
- Building Recommender Systems with Machine Learning and AI (by Frank Kane, Frank Kane)
- 참고로, 유명한 서적들이라 관련 번역서들도 제법있다.
- 국내서(번역서 포함) : 개인적으로 유익했던 또 많은 추천을 받은 책을 간추려 보았다.
- 패턴인식 (오일석 저)
- 빅데이터 기초:개념, 동인, 기법 (Thomas Erl, Wajid Khattak, Paul Buhler 저)
- 인공지능 시대의 비즈니스 전략 (정도희 저)
- 데이터 마이닝 개념과 기법 (지아웨이 한, 미셸린 캠버, 지안 페이 공저)
- 수리통계학 개론 (Hogg, Mckean, Craig 저)
- 수리통계학 (김우철 저)
- 밑바닥부터 시작하는 딥러닝 (사이토 고키 저)
- 핸즈온 머신러닝 (오렐리앙 제롱 저)
- 케라스 창시자에게 배우는 딥러닝 (프랑소와 숄레 저) : 초보자 강추, 참고문헌이 주석으로 제시
- 커뮤니티
- 온라인 교육
- 쿄세라
- 패스트캠퍼스
- 인프런
- DS스쿨
- 인사이트 캠퍼스
- 탈잉
- 무크
- 데이터셋 제공 사이트
- 무비렌즈
(참고) AI 활용사례
위에서 언급한 방향을 찾기 위해 지금까지 구현된 서비스 혹은 제품을 통해 자신에게 적합한 분야를 찾는 인사이트를 얻는 것도 좋은 방법이다.
- 추천시스템
- RateMyDrive
- Acxiom DB
- DHL의 배송 타이밍 관리 및 물류망 구축, 물류센터 확장 및 배송차량 추가 등 투자결정,
- 코로나 확산 상황 등 재해 예측
- 의료 및 헬스케어 분야의 AI 논문 학습
- AI스피커, 자율자동차
- 제조공정 기술, 교육, 마케팅
- 보안 이상탐지, 스팸메일 탐지, 아마존 가드듀티 등
(참고) 데이터 사이언티스트의 진정한 의미
서두에 데이터 사이언티스트의 의미를 광의적으로 정의한 후 본 포스팅을 작성하였지만 사실 필자는 평소 본 단어를 굉장히 협의적으로 해석한다. 짧게 말해 정말 과학자 칭호를 얻을 자격이 있는 분들을 데이터 사이언티스트라고 말한다. 국내 데이터 사이언티스트로 유명한 분들도 본인 스스로를 데이터 사이언티스트라고 표현하지 못할 정도로 고수일수록 조심스러운 단어이다. 그렇다면 협의적인 의미에서 이들은 어떤 능력을 갖추고 있을지 간추려본다. (정확하지는 않겠지만 사실 필자의 목표를 정리한 글이다.)
- 필수 역량
- 수학, 수리통계학에서 연구된 핵심 개념을 프로젝트 전반의 과정에서 언제, 어디에 쓸 수 있는지 선택, 적용, 고안할 수 있는 능력
- 모델을 직접 선택할 수 있음은 물론 고안하고, 변형할 수 있는 능력
- 데이터 및 업무의 성격에 따라 휴리스틱 요소 즉, 파라미터 조정, 신경망 구조 변경등에 오버헤드를 줄이는 경험에 따른 감각
- 모델의 재구성 : 엣지 네트뤄크 구성, 레이어, 뉴런의 개수, 파라미터 튜닝, 활성화 함수 등의 변화
- 선택 역량
- 문제 인식 및 정의 등 비지니스적 인사이트
- 전처리 능력. 모델은 데이터에 의존적이기 때문에 알맞은 모델을 찾기 위한 분석, 더불어 모델의 성능을 극대화할 수 있는 인풋의 변환 능력이 필요하다.
- 실무에 데이터는 없거나, 쓸 수 없는 형태이거나 둘 중 하나이다.
- 비정형, 정규화, 표준화 이슈부터 결측치, 이상치, 센서 오작동으로 인한 오류는 말할것도 없고 시간 규격의 불일치, 기후와 고도에 따른 특수성도 존재한다.
- ML/DL 엔지니어링에서 애플리케이션 서빙에 이르기까지 전반의 IT 프로젝트 진행 능력 및 아키텍처 설계 능력
(참고) 그 외의 학습조언
- IT개발자라면 코딩 구현 보다는 수리통계학에 조금 더 관심을 가졌으면 한다.
- 예를들면 기본적인 선형회귀가 1차 방정식인 것은 잘 알아도 충족조건은 잘 모른다.
- 등분산성(전차의 분산이 같아야 한다.), 정규분포(잔차가 정규분포를 띄어야 한다.)
- 데이터 유형을 알아야 한다. 예) 명서등비, 이진, 숫자, 이산/연속 등, 전처리(정제/통합/축소/변환) 포함
- 빈발 패턴, 아웃라이어 분석, 퍼지 세트, 베이즈정리, 최대가능도 추정 정도는 알아야 한다.
- 빅데이터 시대에 들어서면서 추정, 검정, p-value는 상대적으로 중요도가 떨어진다.
- 확률분포 : 정규, 지수, 감마, 카이제곱, 포아송, 이항, 다리클레, 결합, 주변 등
- 예를들면 기본적인 선형회귀가 1차 방정식인 것은 잘 알아도 충족조건은 잘 모른다.
- 수학의 엄밀한 증명은 피하고 집합론, 해석학으로 이해를 보충하고 활용에 초점을 맞춘다.
- 딥러닝 노드의 활성화 함수 : 거듭 합성함수 꼴로 표현되며, 어떤 데이터도 복잡한 함수로 표현이 가능하여 표현력이 좋아진다.
- 국내 빅데이터 분석 SI 업체 : 솔트룩스, 모비젠, 엔텔스, 와이즈넛 등
마무리
본 포스팅은 그동안 개인적으로 읽었던 출간된 도서, 지인의 조언, 유튜브 등 고수들의 개인 채널, 블로그 등을 망라하여 필자 스스로 좋은 데이터 사이언티스트가 되기 위한 방향을 정리하고자 작성한 글이다. 따라서 절대 맹신하지 말고 참고로 삼아 더 좋은 방향을 찾으셨으면 한다.
긴 글 읽어주심에 감사드리며 필자와 같이 열정은 있으나 현실이 막막한 분들께 조금이라도 도움이 되길 간절히 바란다. (참고 - 현재 버전은 초안이며, 글의 내용이 길어 앞으로 계속 보완해나갈 예정입니다.)

{kind=link}